文章从kaggle上参加的一个比赛的kernel上导出来的,不太规范,有空整理。
Introduction
The U.S. has almost 500 students for every guidance counselor. Underserved youth lack the network to find their career role models, making CareerVillage.org the only option for millions of young people in America and around the globe with nowhere else to turn.
Our goal is to develop a method tp recommend relevant questions to the professionals who are most likely to answer them.
1 | import numpy as np # linear algebra |
1 | emails = pd.read_csv('./data/input/emails.csv') #Each email corresponds to one specific email to one specific recipient. The frequency_level refers to the type of email template which includes immediate emails sent right after a question is asked, daily digests, and weekly digests. |
1 | emails.head(10) |
| emails_id | emails_recipient_id | emails_date_sent | emails_frequency_level | |
|---|---|---|---|---|
| 0 | 2337714 | 0c673e046d824ec0ad0ebe012a0673e4 | 2018-12-07 01:05:40 UTC+0000 | email_notification_daily |
| 1 | 2336077 | 0c673e046d824ec0ad0ebe012a0673e4 | 2018-12-06 01:14:15 UTC+0000 | email_notification_daily |
| 2 | 2314660 | 0c673e046d824ec0ad0ebe012a0673e4 | 2018-11-17 00:38:27 UTC+0000 | email_notification_daily |
| 3 | 2312639 | 0c673e046d824ec0ad0ebe012a0673e4 | 2018-11-16 00:32:19 UTC+0000 | email_notification_daily |
| 4 | 2299700 | 0c673e046d824ec0ad0ebe012a0673e4 | 2018-11-08 00:16:40 UTC+0000 | email_notification_daily |
| 5 | 2288533 | 0c673e046d824ec0ad0ebe012a0673e4 | 2018-11-02 23:02:12 UTC+0000 | email_notification_daily |
| 6 | 2280818 | 0c673e046d824ec0ad0ebe012a0673e4 | 2018-10-30 00:54:31 UTC+0000 | email_notification_daily |
| 7 | 2270520 | 0c673e046d824ec0ad0ebe012a0673e4 | 2018-10-25 23:44:41 UTC+0000 | email_notification_daily |
| 8 | 2269277 | 0c673e046d824ec0ad0ebe012a0673e4 | 2018-10-25 02:46:00 UTC+0000 | email_notification_daily |
| 9 | 2267396 | 0c673e046d824ec0ad0ebe012a0673e4 | 2018-10-24 04:42:34 UTC+0000 | email_notification_daily |
1 | questions.head(10) |
| questions_id | questions_author_id | questions_date_added | questions_title | questions_body | |
|---|---|---|---|---|---|
| 0 | 332a511f1569444485cf7a7a556a5e54 | 8f6f374ffd834d258ab69d376dd998f5 | 2016-04-26 11:14:26 UTC+0000 | Teacher career question | What is a maths teacher? what is a ma... |
| 1 | eb80205482e4424cad8f16bc25aa2d9c | acccbda28edd4362ab03fb8b6fd2d67b | 2016-05-20 16:48:25 UTC+0000 | I want to become an army officer. What can I d... | I am Priyanka from Bangalore . Now am in 10th ... |
| 2 | 4ec31632938a40b98909416bdd0decff | f2c179a563024ccc927399ce529094b5 | 2017-02-08 19:13:38 UTC+0000 | Will going abroad for your first job increase ... | I'm planning on going abroad for my first job.... |
| 3 | 2f6a9a99d9b24e5baa50d40d0ba50a75 | 2c30ffba444e40eabb4583b55233a5a4 | 2017-09-01 14:05:32 UTC+0000 | To become a specialist in business management... | i hear business management is a hard way to ge... |
| 4 | 5af8880460c141dbb02971a1a8369529 | aa9eb1a2ab184ebbb00dc01ab663428a | 2017-09-01 02:36:54 UTC+0000 | Are there any scholarships out there for stude... | I'm trying to find scholarships for first year... |
| 5 | 7c336403258f4da3a2e0955742c76462 | d1e4587c0e784c62bc27eb8d16a07f38 | 2017-03-01 04:27:08 UTC+0000 | How many years of coege do you need to be an e... | To be an engineer #united-states |
| 6 | be3c5edfdb07423e955e9b2d7f186bce | 71b4554d4a824253aa28287372c55797 | 2017-09-01 04:59:38 UTC+0000 | I want to become a doctor because of my great ... | I am a musician and want to pursue that in col... |
| 7 | 0f1d6a4f276c4a05878dd48e03e52289 | 585ac233015447cc9e9a217044e515e1 | 2016-05-19 22:16:25 UTC+0000 | what kind of college could i go to for a soc... | I like soccer because i been playing sense i w... |
| 8 | d4999cdc470049a1a3382c4b5f14a7aa | 654e1d6fd5b947249c0e70658d01b2ac | 2017-08-31 19:20:47 UTC+0000 | What are the college classes like for and grap... | I'm asking because I was thinking about choosi... |
| 9 | e214acfbe6644d65b889a3268828db9d | 16908136951a48ed942738822cedd5c2 | 2012-09-09 05:33:25 UTC+0000 | what does it take to be an anesthesiologist? | I am a sophomore who is interested in learning... |
1 | professionals.head(10) |
| professionals_id | professionals_location | professionals_industry | professionals_headline | professionals_date_joined | |
|---|---|---|---|---|---|
| 0 | 9ced4ce7519049c0944147afb75a8ce3 | NaN | NaN | NaN | 2011-10-05 20:35:19 UTC+0000 |
| 1 | f718dcf6d2ec4cb0a52a9db59d7f9e67 | NaN | NaN | NaN | 2011-10-05 20:49:21 UTC+0000 |
| 2 | 0c673e046d824ec0ad0ebe012a0673e4 | New York, New York | NaN | NaN | 2011-10-18 17:31:26 UTC+0000 |
| 3 | 977428d851b24183b223be0eb8619a8c | Boston, Massachusetts | NaN | NaN | 2011-11-09 20:39:29 UTC+0000 |
| 4 | e2d57e5041a44f489288397c9904c2b2 | NaN | NaN | NaN | 2011-12-10 22:14:44 UTC+0000 |
| 5 | c9bfa93898594cbbace436deca644c64 | NaN | NaN | NaN | 2011-12-12 14:25:46 UTC+0000 |
| 6 | ed85488fb5e941eaa97014137fcbf317 | NaN | NaN | NaN | 2011-12-28 03:02:04 UTC+0000 |
| 7 | 102fb92c28034ad988b593d0111cb4bb | NaN | NaN | NaN | 2011-12-26 05:00:00 UTC+0000 |
| 8 | 5a4a16842ec64430ac3f916aacf35fe1 | NaN | NaN | NaN | 2011-12-26 05:00:00 UTC+0000 |
| 9 | 81999d5ad93549dab55636a545e84f2a | NaN | NaN | NaN | 2011-12-26 05:00:00 UTC+0000 |
1 | comments.head(10) |
| comments_id | comments_author_id | comments_parent_content_id | comments_date_added | comments_body | |
|---|---|---|---|---|---|
| 0 | f30250d3c2ca489db1afa9b95d481e08 | 9fc88a7c3323466dbb35798264c7d497 | b476f9c6d9cd4c50a7bacdd90edd015a | 2019-01-31 23:39:40 UTC+0000 | First, you speak to recruiters. They are train... |
| 1 | ca9bfc4ba9464ea383a8b080301ad72c | de2415064b9b445c8717425ed70fd99a | ef4b6ae24d1f4c3b977731e8189c7fd7 | 2019-01-31 20:30:47 UTC+0000 | Most large universities offer study abroad pro... |
| 2 | c354f6e33956499aa8b03798a60e9386 | 6ed20605002a42b0b8e3d6ac97c50c7f | ca7a9d7a95df471c816db82ee758f57d | 2019-01-31 18:44:04 UTC+0000 | First, I want to put you at ease that the oppo... |
| 3 | 73a6223948714c5da6231937157e4cb7 | d02f6d9faac24997a7003a59e5f34bd3 | c7a88aa76f5f49b0830bfeb46ba17e4d | 2019-01-31 17:53:28 UTC+0000 | Your question submission was great! I just wan... |
| 4 | 55a89a9061d44dd19569c45f90a22779 | e78f75c543e84e1c94da1801d8560f65 | c7a88aa76f5f49b0830bfeb46ba17e4d | 2019-01-31 14:51:53 UTC+0000 | Thank you. I'm new to this site. I'm sorry if ... |
| 5 | 3661006cdb6f4595b193b8d9fbe21228 | d02f6d9faac24997a7003a59e5f34bd3 | 30901132449849b2aa18f308306e89a2 | 2019-01-30 23:15:54 UTC+0000 | My pleasure! I'm so glad I was helpful! |
| 6 | 2e0fd25e53bd4f6a838210d1addc50f3 | da98e5a8fc6748ccac91d0951368e71f | 5bf762c8501d450a97af992800980242 | 2019-01-30 18:03:00 UTC+0000 | My suggestion is to fix a certain time to focu... |
| 7 | 82934dc63c7044b4922750024d8a51ca | a303c1c4faef4adda38fcd4c0d2bade1 | dee2a0bb57f446578fc9c73b745c7b15 | 2019-01-29 18:01:00 UTC+0000 | I have a different view from Ogechi's answer. ... |
| 8 | 8e319089858640779761122f270e8449 | 4e7876eee5b947f39602db35f4dd8162 | 30901132449849b2aa18f308306e89a2 | 2019-01-29 15:14:38 UTC+0000 | Thanks so much for your answer, Bryant and wil... |
| 9 | 9dc4c77e87bd406ba851628e290027b3 | c1297398b70744f9a1a4ba200af28ebe | 7ebb0e5e9b544c1eb0c96ffad1d73dfd | 2019-01-29 08:29:30 UTC+0000 | here’s another from a question 4 years ago\r\n... |
1 | tag_users.head(10) |
| tag_users_tag_id | tag_users_user_id | |
|---|---|---|
| 0 | 593 | c72ab38e073246e88da7e9a4ec7a4472 |
| 1 | 1642 | 8db519781ec24f2e8bdc67c2ac53f614 |
| 2 | 638 | 042d2184ee3e4e548fc3589baaa69caf |
| 3 | 11093 | c660bd0dc1b34224be78a58aa5a84a63 |
| 4 | 21539 | 8ce1dca4e94240239e4385ed22ef43ce |
| 5 | 1047 | 3330f8a7835346a2a91f9393ae21efee |
| 6 | 64 | 5a4a16842ec64430ac3f916aacf35fe1 |
| 7 | 1139 | 461f92b955924604832a92b6bc14ac1d |
| 8 | 55 | 7daf1e6dfb3443b99b240890f0a4d69b |
| 9 | 54 | 7daf1e6dfb3443b99b240890f0a4d69b |
1 | answers.head(10) |
| answers_id | answers_author_id | answers_question_id | answers_date_added | answers_body | |
|---|---|---|---|---|---|
| 0 | 4e5f01128cae4f6d8fd697cec5dca60c | 36ff3b3666df400f956f8335cf53e09e | 332a511f1569444485cf7a7a556a5e54 | 2016-04-29 19:40:14 UTC+0000 | <p>Hi!</p>\n<p>You are asking a very interesti... |
| 1 | ada720538c014e9b8a6dceed09385ee3 | 2aa47af241bf42a4b874c453f0381bd4 | eb80205482e4424cad8f16bc25aa2d9c | 2018-05-01 14:19:08 UTC+0000 | <p>Hi. I joined the Army after I attended coll... |
| 2 | eaa66ef919bc408ab5296237440e323f | cbd8f30613a849bf918aed5c010340be | eb80205482e4424cad8f16bc25aa2d9c | 2018-05-02 02:41:02 UTC+0000 | <p>Dear Priyanka,</p><p>Greetings! I have answ... |
| 3 | 1a6b3749d391486c9e371fbd1e605014 | 7e72a630c303442ba92ff00e8ea451df | 4ec31632938a40b98909416bdd0decff | 2017-05-10 19:00:47 UTC+0000 | <p>I work for a global company who values high... |
| 4 | 5229c514000446d582050f89ebd4e184 | 17802d94699140b0a0d2995f30c034c6 | 2f6a9a99d9b24e5baa50d40d0ba50a75 | 2017-10-13 22:07:33 UTC+0000 | I agree with Denise. Every single job I've had... |
| 5 | 5f62fadae80748c7907e3b0551bf4203 | b03c3872daeb4a5cb1d8cd510942f0c4 | 2f6a9a99d9b24e5baa50d40d0ba50a75 | 2017-10-12 16:01:44 UTC+0000 | Networking is a key component to progressing y... |
| 6 | 1d804b3b9e764cdd90195fb138d1a5aa | f6c89fde797d45938bce3531f55c9b6b | 5af8880460c141dbb02971a1a8369529 | 2017-09-29 18:50:11 UTC+0000 | https://www.unigo.com/\n\nCheck out this websi... |
| 7 | 08d3cf6fa20543ddbdc42f70a7bcae9e | 5bc2db4d58584f95bdba30ed2c21d573 | 5af8880460c141dbb02971a1a8369529 | 2018-06-08 02:39:02 UTC+0000 | <p>Hi Jocelyn ,</p><p><br></p><p>May I recomme... |
| 8 | 9d33d099a03c44328fbf166aad585f63 | 8136c8653d3a4895b49cac90b88120d2 | 7c336403258f4da3a2e0955742c76462 | 2017-03-01 16:52:43 UTC+0000 | <p>For the typical schedule it takes four year... |
| 9 | 228e5feefb4e42188b7c48a5c7eb3aa8 | 35c8d979b56647839c8df0f0383648cd | be3c5edfdb07423e955e9b2d7f186bce | 2017-10-13 18:08:20 UTC+0000 | Of course! I know someone who doubled in class... |
1 | group_memberships.head(10) |
| group_memberships_group_id | group_memberships_user_id | |
|---|---|---|
| 0 | eabbdf4029734c848a9da20779637d03 | 9a5aead62c344207b2624dba90985dc5 |
| 1 | eabbdf4029734c848a9da20779637d03 | ea7122da1c7b4244a2184a4f9f944053 |
| 2 | eabbdf4029734c848a9da20779637d03 | cba603f34acb4a40b3ccb53fe6681b5d |
| 3 | eabbdf4029734c848a9da20779637d03 | fa9a126e63714641ae0145557a390cab |
| 4 | eabbdf4029734c848a9da20779637d03 | 299da113c5d1420ab525106c242c9429 |
| 5 | 7080bf8dcf78463bb03e6863887fd715 | 836a747118d6436caf56ff3a3c47289a |
| 6 | 7080bf8dcf78463bb03e6863887fd715 | 82cf96ae74fa4b3a8ffd8a74446c08ca |
| 7 | 7080bf8dcf78463bb03e6863887fd715 | b0f6c44506444fb99e910dcc5836b5d8 |
| 8 | bc6fc50a2b444efc8ec47111b290ffb8 | ab8d405cfdab4faf83ffe7f83944a87b |
| 9 | bc6fc50a2b444efc8ec47111b290ffb8 | 370dba85f183496186772be0c53a69b1 |
1 | tags.head(10) |
| tags_tag_id | tags_tag_name | |
|---|---|---|
| 0 | 27490 | college |
| 1 | 461 | computer-science |
| 2 | 593 | computer-software |
| 3 | 27292 | business |
| 4 | 18217 | doctor |
| 5 | 54 | engineering |
| 6 | 129 | career |
| 7 | 89 | medicine |
| 8 | 53 | science |
| 9 | 55 | engineer |
1 | students.head(10) |
| students_id | students_location | students_date_joined | |
|---|---|---|---|
| 0 | 12a89e96755a4dba83ff03e03043d9c0 | NaN | 2011-12-16 14:19:24 UTC+0000 |
| 1 | e37a5990fe354c60be5e87376b08d5e3 | NaN | 2011-12-27 03:02:44 UTC+0000 |
| 2 | 12b402cceeda43dcb6e12ef9f2d221ea | NaN | 2012-01-01 05:00:00 UTC+0000 |
| 3 | a0f431fc79794edcb104f68ce55ab897 | NaN | 2012-01-01 05:00:00 UTC+0000 |
| 4 | 23aea4702d804bd88d1e9fb28074a1b4 | NaN | 2012-01-01 05:00:00 UTC+0000 |
| 5 | 18a8f9363cd24a37b690e1b205146b14 | NaN | 2012-01-01 05:00:00 UTC+0000 |
| 6 | d21c67279ada49d1bcf66ad620c00911 | NaN | 2012-01-01 05:00:00 UTC+0000 |
| 7 | 433c0f5f90344453ba50ec8aee5fdfa4 | NaN | 2012-01-01 05:00:00 UTC+0000 |
| 8 | f0a7d23c3d374f8d9a1a5eb9b96eab0f | NaN | 2012-01-01 05:00:00 UTC+0000 |
| 9 | 26269f6765b74347b28155aea1b57393 | NaN | 2012-01-01 05:00:00 UTC+0000 |
1 | groups.head(10) |
| groups_id | groups_group_type | |
|---|---|---|
| 0 | eabbdf4029734c848a9da20779637d03 | youth program |
| 1 | 7080bf8dcf78463bb03e6863887fd715 | youth program |
| 2 | bc6fc50a2b444efc8ec47111b290ffb8 | youth program |
| 3 | 37f002e8d5e442ca8e36e972eaa55882 | youth program |
| 4 | 52419ff84d4b47bebd0b0a6c1263c296 | youth program |
| 5 | 559dbc7bd1f64c268ff149c4d5d63500 | youth program |
| 6 | 528fa2c7559a40749b6151a07d3b8ef5 | youth program |
| 7 | cfaac1762bed4c8bb88696267129a560 | youth program |
| 8 | f79273f51df849d298bd6f4b86daee99 | youth program |
| 9 | ba94226c87d249a1a2dbdc32a848b769 | youth program |
1 | matches.head(10) |
| matches_email_id | matches_question_id | |
|---|---|---|
| 0 | 1721939 | 332a511f1569444485cf7a7a556a5e54 |
| 1 | 1665388 | 332a511f1569444485cf7a7a556a5e54 |
| 2 | 1636634 | 332a511f1569444485cf7a7a556a5e54 |
| 3 | 1635498 | 332a511f1569444485cf7a7a556a5e54 |
| 4 | 1620298 | 332a511f1569444485cf7a7a556a5e54 |
| 5 | 1618336 | 332a511f1569444485cf7a7a556a5e54 |
| 6 | 1610422 | 332a511f1569444485cf7a7a556a5e54 |
| 7 | 1601694 | 332a511f1569444485cf7a7a556a5e54 |
| 8 | 1568908 | 332a511f1569444485cf7a7a556a5e54 |
| 9 | 1551730 | 332a511f1569444485cf7a7a556a5e54 |
1 | tag_questions.head(10) |
| tag_questions_tag_id | tag_questions_question_id | |
|---|---|---|
| 0 | 28930 | cb43ebee01364c68ac61d347a393ae39 |
| 1 | 28930 | 47f55e85ce944242a5a347ab85a8ffb4 |
| 2 | 28930 | ccc30a033a0f4dfdb2eb987012f25792 |
| 3 | 28930 | e30b274e48d741f7bf50eb5e7171a3c0 |
| 4 | 28930 | 3d22742052df4989b311b4195cbb0f1a |
| 5 | 28930 | c79baebeb6d44726b6f70a2414fb69bc |
| 6 | 28930 | 4eb64ed1527847f29d3e3d8a713bb3dc |
| 7 | 28930 | bebfb741f4524b8cb871f35b5780b54f |
| 8 | 28930 | 3e7c462a0adb4bfa8830282867f3900b |
| 9 | 28930 | 23b52dd81ad7465a9472596c7dedc492 |
Create a function to merging tables more easily.
1 | def merging(df1, df2, left, right): |
Merging questions with answers.
1 | qa = merging(questions, answers, "questions_id", "answers_question_id") |
| 0 | 1 | 2 | |
|---|---|---|---|
| questions_id | 332a511f1569444485cf7a7a556a5e54 | eb80205482e4424cad8f16bc25aa2d9c | eb80205482e4424cad8f16bc25aa2d9c |
| questions_author_id | 8f6f374ffd834d258ab69d376dd998f5 | acccbda28edd4362ab03fb8b6fd2d67b | acccbda28edd4362ab03fb8b6fd2d67b |
| questions_date_added | 2016-04-26 11:14:26 UTC+0000 | 2016-05-20 16:48:25 UTC+0000 | 2016-05-20 16:48:25 UTC+0000 |
| questions_title | Teacher career question | I want to become an army officer. What can I d... | I want to become an army officer. What can I d... |
| questions_body | What is a maths teacher? what is a ma... | I am Priyanka from Bangalore . Now am in 10th ... | I am Priyanka from Bangalore . Now am in 10th ... |
| answers_id | 4e5f01128cae4f6d8fd697cec5dca60c | ada720538c014e9b8a6dceed09385ee3 | eaa66ef919bc408ab5296237440e323f |
| answers_author_id | 36ff3b3666df400f956f8335cf53e09e | 2aa47af241bf42a4b874c453f0381bd4 | cbd8f30613a849bf918aed5c010340be |
| answers_question_id | 332a511f1569444485cf7a7a556a5e54 | eb80205482e4424cad8f16bc25aa2d9c | eb80205482e4424cad8f16bc25aa2d9c |
| answers_date_added | 2016-04-29 19:40:14 UTC+0000 | 2018-05-01 14:19:08 UTC+0000 | 2018-05-02 02:41:02 UTC+0000 |
| answers_body | <p>Hi!</p>\n<p>You are asking a very interesti... | <p>Hi. I joined the Army after I attended coll... | <p>Dear Priyanka,</p><p>Greetings! I have answ... |
Exploring questions_answers (1)
Can we find out how long does it take for a question to be answered?
1 | qa['questions_date_added'] = pd.to_datetime(qa['questions_date_added']) |
1 | qa.head().T |
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| questions_id | 332a511f1569444485cf7a7a556a5e54 | eb80205482e4424cad8f16bc25aa2d9c | eb80205482e4424cad8f16bc25aa2d9c | 4ec31632938a40b98909416bdd0decff | 2f6a9a99d9b24e5baa50d40d0ba50a75 |
| questions_author_id | 8f6f374ffd834d258ab69d376dd998f5 | acccbda28edd4362ab03fb8b6fd2d67b | acccbda28edd4362ab03fb8b6fd2d67b | f2c179a563024ccc927399ce529094b5 | 2c30ffba444e40eabb4583b55233a5a4 |
| questions_date_added | 2016-04-26 11:14:26 | 2016-05-20 16:48:25 | 2016-05-20 16:48:25 | 2017-02-08 19:13:38 | 2017-09-01 14:05:32 |
| questions_title | Teacher career question | I want to become an army officer. What can I d... | I want to become an army officer. What can I d... | Will going abroad for your first job increase ... | To become a specialist in business management... |
| questions_body | What is a maths teacher? what is a ma... | I am Priyanka from Bangalore . Now am in 10th ... | I am Priyanka from Bangalore . Now am in 10th ... | I'm planning on going abroad for my first job.... | i hear business management is a hard way to ge... |
| answers_id | 4e5f01128cae4f6d8fd697cec5dca60c | ada720538c014e9b8a6dceed09385ee3 | eaa66ef919bc408ab5296237440e323f | 1a6b3749d391486c9e371fbd1e605014 | 5229c514000446d582050f89ebd4e184 |
| answers_author_id | 36ff3b3666df400f956f8335cf53e09e | 2aa47af241bf42a4b874c453f0381bd4 | cbd8f30613a849bf918aed5c010340be | 7e72a630c303442ba92ff00e8ea451df | 17802d94699140b0a0d2995f30c034c6 |
| answers_question_id | 332a511f1569444485cf7a7a556a5e54 | eb80205482e4424cad8f16bc25aa2d9c | eb80205482e4424cad8f16bc25aa2d9c | 4ec31632938a40b98909416bdd0decff | 2f6a9a99d9b24e5baa50d40d0ba50a75 |
| answers_date_added | 2016-04-29 19:40:14 | 2018-05-01 14:19:08 | 2018-05-02 02:41:02 | 2017-05-10 19:00:47 | 2017-10-13 22:07:33 |
| answers_body | <p>Hi!</p>\n<p>You are asking a very interesti... | <p>Hi. I joined the Army after I attended coll... | <p>Dear Priyanka,</p><p>Greetings! I have answ... | <p>I work for a global company who values high... | I agree with Denise. Every single job I've had... |
| qa_duration | 3 | 710 | 711 | 90 | 42 |
1 | # after groupby, head(1) returns the first occurrence |
1 | # let's explore data from last year |
1 | week_val_cnt = first_qa['week'].value_counts().sort_index() |
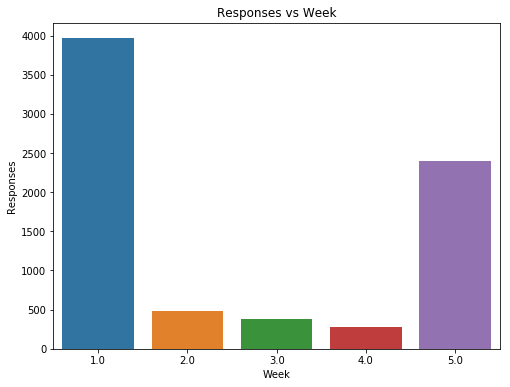
1 | week_val_cnt |
1.0 3967
2.0 480
3.0 375
4.0 284
5.0 2403
Name: week, dtype: int64
Exploring questions and answers (2) and mind-blowing observation
We continue exploring the question body to understand why some questions have longer response time.
1 | def process_text(df, col): |
1 | first_qa['questions_body'] = process_text(first_qa, 'questions_body')['questions_body'] |
1 | dist_fast = fast_resp.apply(lambda x: len(x.split(' '))) |
1 | pal = sns.color_palette() |
Text(0,0.5,'Probability')
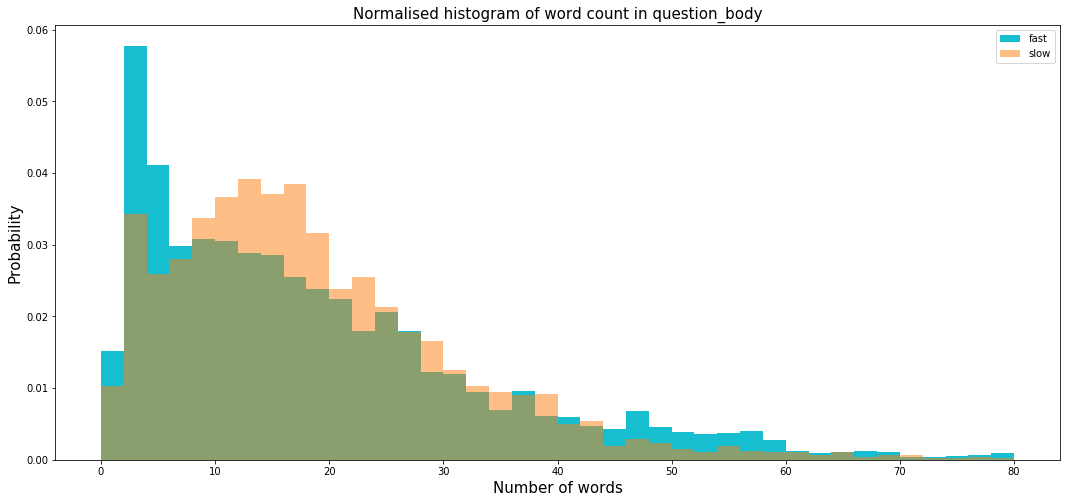
Wow! Seems like longer questions tend to have longer response time.
1 | from wordcloud import WordCloud |
(-0.5, 1439.5, 1079.5, -0.5)
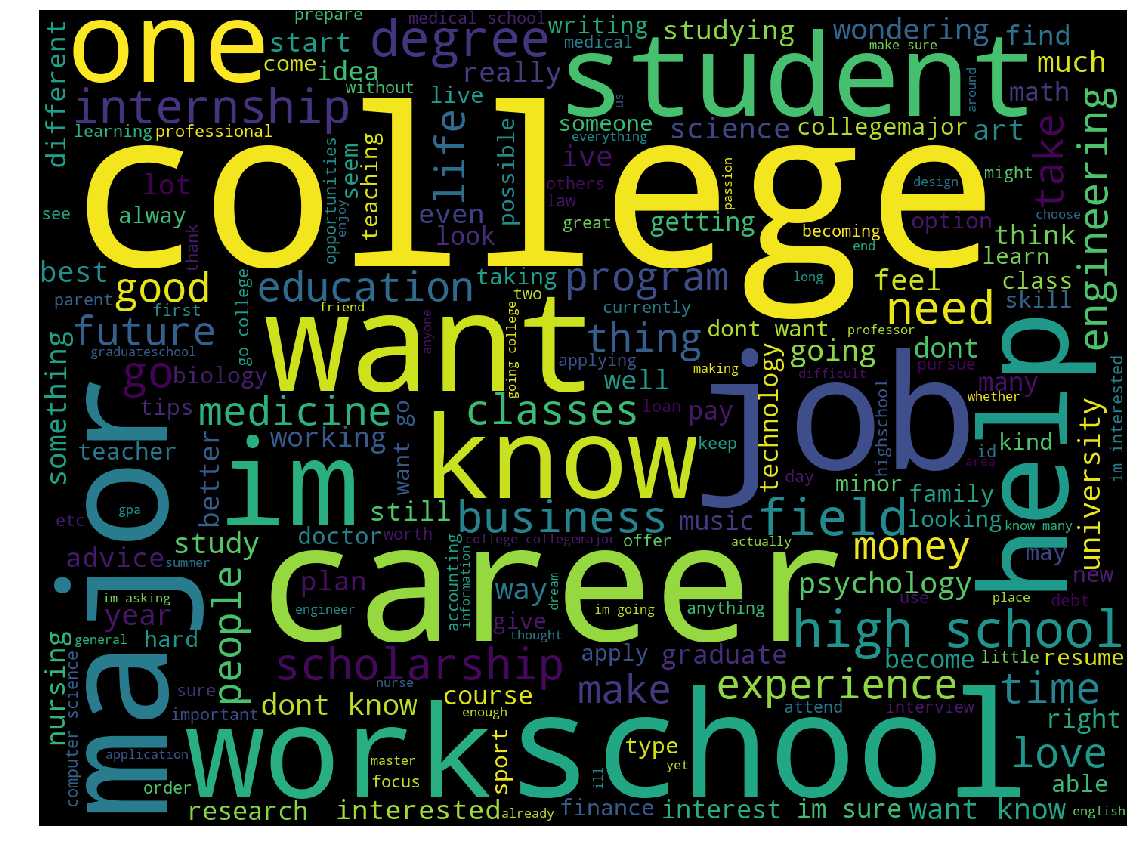
Unsurprisingly, we see big college and career.
What else differentiates a fast response and slow response question?
1 | tf = TfidfVectorizer(analyzer='word', |
1 | # sum of the scores of each word |
1 | print('fast_vocab\'s words and score:') |
fast_vocab's words and score:
2674
word: engineering, score: 75.402
word: major, score: 79.043
word: like, score: 79.420
word: job, score: 81.481
word: know, score: 102.191
word: school, score: 108.659
word: im, score: 121.079
word: want, score: 121.301
word: career, score: 131.120
word: college, score: 216.177
1 | print('slow_vocab\'s words and score:') |
slow_vocab's words and score:
1881
word: medicine, score: 45.072
word: major, score: 49.781
word: like, score: 52.039
word: career, score: 52.103
word: scholarships, score: 60.325
word: school, score: 68.618
word: know, score: 69.904
word: im, score: 72.984
word: want, score: 90.048
word: college, score: 130.133
IMPORTANT OBSERVATION:
- Question body of slow responses are LONGER than that of fast response.
- Question body of slow responses are DIFFICULT to answer! They require more expertise to answer!
Exploring students
Where do the students come from if they are from the US?
1 | state_codes = {'District of Columbia' : 'DC','Mississippi': 'MS', 'Oklahoma': 'OK', |
1 | students['students_location'] = students['students_location'].fillna('') |
California 4539
Texas 2716
New York 1783
Florida 1478
Massachusetts 1051
Illinois 962
Karnataka 896
Pennsylvania 725
Georgia 722
Tamil Nadu 678
Name: students_location, dtype: int64
1 | us_states = [] |
1 | df = pd.DataFrame({'states': s_val_cnt.index, |
1 | data = [ dict( |
1 | qap = merging(qa, professionals, "answers_author_id", "professionals_id") |
| 0 | 1 | 2 | |
|---|---|---|---|
| questions_id | f6b9ca94aed04ba28256492708e74f60 | f6b9ca94aed04ba28256492708e74f60 | ca209b4e19064d8e9834b3ca1a3f5361 |
| questions_author_id | 05444a2f42454327b2ac4b463c0adbe0 | 05444a2f42454327b2ac4b463c0adbe0 | 05444a2f42454327b2ac4b463c0adbe0 |
| questions_date_added | 2011-09-27 15:26:19 | 2011-09-27 15:26:19 | 2011-09-27 15:27:14 |
| questions_title | What do top tier consulting firms look for in ... | What do top tier consulting firms look for in ... | What is the path to get from high school to be... |
| questions_body | Please explain the factors consulting firms lo... | Please explain the factors consulting firms lo... | What are some of the paths to getting from beg... |
| answers_id | 7640a6e5d5224c8681cc58de860858f4 | 71229eb293314c8a9e545057ecc32c93 | 7d1a41e5ef48410fa7ff647a4bf87eed |
| answers_author_id | 9ced4ce7519049c0944147afb75a8ce3 | 0c673e046d824ec0ad0ebe012a0673e4 | 0c673e046d824ec0ad0ebe012a0673e4 |
| answers_question_id | f6b9ca94aed04ba28256492708e74f60 | f6b9ca94aed04ba28256492708e74f60 | ca209b4e19064d8e9834b3ca1a3f5361 |
| answers_date_added | 2011-10-05 20:42:09 | 2011-10-18 17:39:49 | 2011-10-18 17:50:45 |
| answers_body | <p>Basically three things: </p>\n<ol>\n<li>Big... | <p>I would echo CriticalMass's answer. People ... | <p>It's a long road to becoming a judge, and n... |
| qa_duration | 8 | 21 | 21 |
| professionals_id | 9ced4ce7519049c0944147afb75a8ce3 | 0c673e046d824ec0ad0ebe012a0673e4 | 0c673e046d824ec0ad0ebe012a0673e4 |
| professionals_location | NaN | New York, New York | New York, New York |
| professionals_industry | NaN | NaN | NaN |
| professionals_headline | NaN | NaN | NaN |
| professionals_date_joined | 2011-10-05 20:35:19 UTC+0000 | 2011-10-18 17:31:26 UTC+0000 | 2011-10-18 17:31:26 UTC+0000 |
What industry do the professionals come from?
1 | p_industry_cnt = professionals['professionals_industry'].value_counts() |
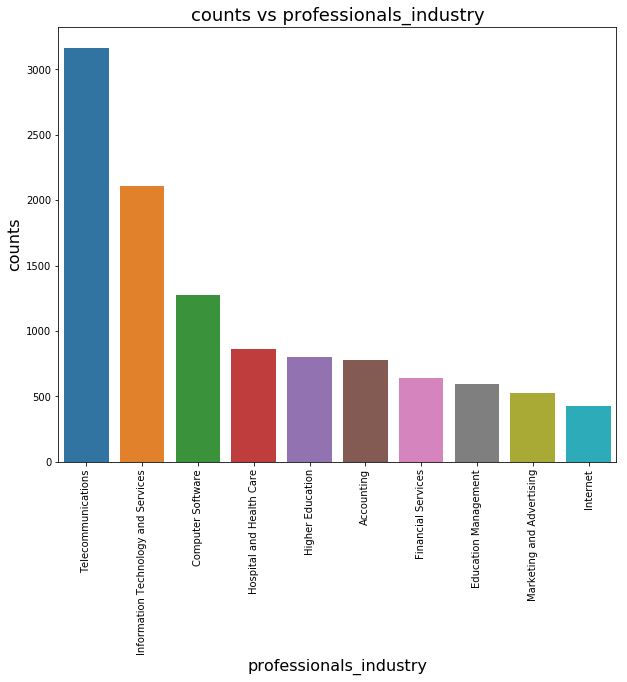
1 | p_industry_cnt.head(10) |
Telecommunications 3166
Information Technology and Services 2109
Computer Software 1272
Hospital and Health Care 862
Higher Education 800
Accounting 781
Financial Services 639
Education Management 593
Marketing and Advertising 526
Internet 427
Name: professionals_industry, dtype: int64
What are the professionals’ headline?
1 | p_cnt = professionals['professionals_headline'].value_counts() |
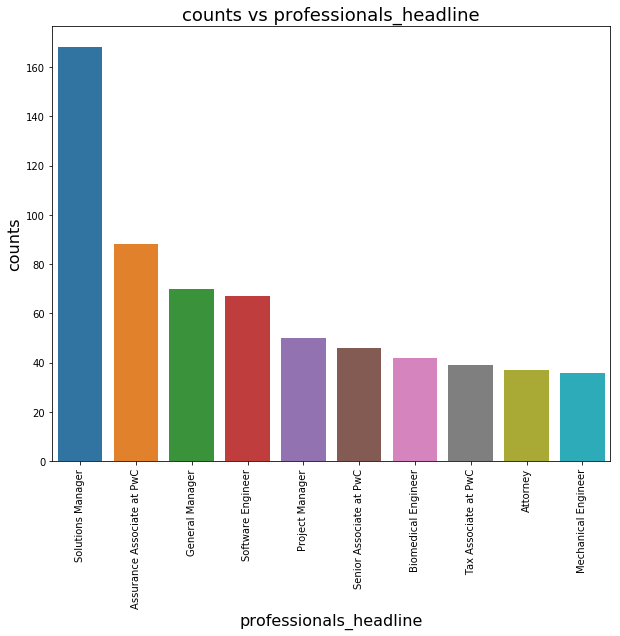
1 | p_cnt.head(10) |
-- 325
Solutions Manager 168
Assurance Associate at PwC 88
General Manager 70
Software Engineer 67
Project Manager 50
Senior Associate at PwC 46
Biomedical Engineer 42
Tax Associate at PwC 39
Attorney 37
Name: professionals_headline, dtype: int64
Who are our biggest heroes?
1 | qap_author_id = qap['answers_author_id'].value_counts() |
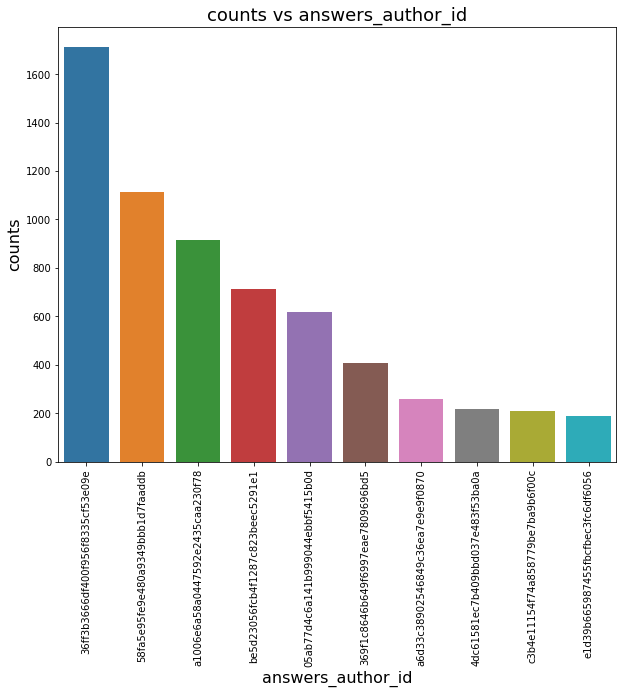
Where do the professionals come from? Let’s remove the city to get a better context.
1 | p = professionals.copy() |
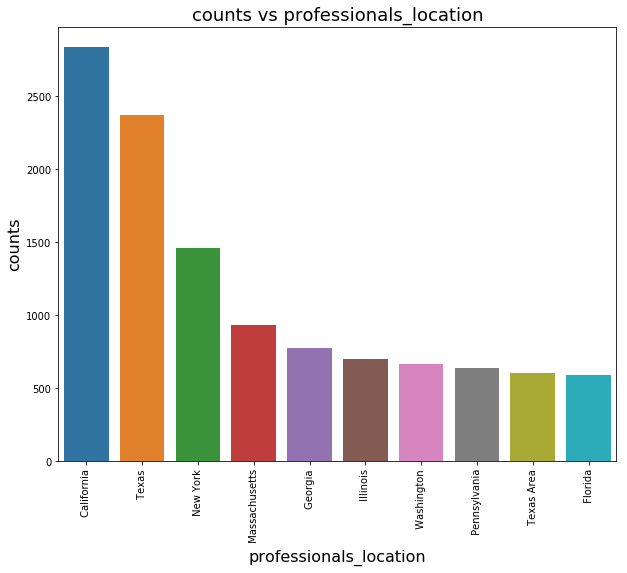
Let’s check for active professionals.
1 | pa = merging(professionals, answers, "professionals_id", "answers_author_id") |
(17225, 1766, 831)
We have 17,225 authors who have answered more than 5 questions and 1,766 authors who at least answered a question in year 2018 since the data was collected up to January 31st of 2019.
Exploring professionals and answers
Let’s take a closer look at the professionals’ answers.
1 | pa = merging(professionals, answers, 'professionals_id' , 'answers_author_id') |
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| professionals_id | 9ced4ce7519049c0944147afb75a8ce3 | 0c673e046d824ec0ad0ebe012a0673e4 | 0c673e046d824ec0ad0ebe012a0673e4 | 0c673e046d824ec0ad0ebe012a0673e4 | 0c673e046d824ec0ad0ebe012a0673e4 |
| professionals_location | NaN | New York, New York | New York, New York | New York, New York | New York, New York |
| professionals_industry | NaN | NaN | NaN | NaN | NaN |
| professionals_headline | NaN | NaN | NaN | NaN | NaN |
| professionals_date_joined | 2011-10-05 20:35:19 UTC+0000 | 2011-10-18 17:31:26 UTC+0000 | 2011-10-18 17:31:26 UTC+0000 | 2011-10-18 17:31:26 UTC+0000 | 2011-10-18 17:31:26 UTC+0000 |
| answers_id | 7640a6e5d5224c8681cc58de860858f4 | f18d7fca363d4b21a81e6683c5a86b96 | 5d670d5f8700402ab56bae609b06d02d | 6d823a750e294c75b10fafbbbaf19855 | 63b7a06323ee4d578a37cf780debfa58 |
| answers_author_id | 9ced4ce7519049c0944147afb75a8ce3 | 0c673e046d824ec0ad0ebe012a0673e4 | 0c673e046d824ec0ad0ebe012a0673e4 | 0c673e046d824ec0ad0ebe012a0673e4 | 0c673e046d824ec0ad0ebe012a0673e4 |
| answers_question_id | f6b9ca94aed04ba28256492708e74f60 | e214acfbe6644d65b889a3268828db9d | 9d211b99e17c46fbbaca03dc6b43f1c4 | e978b437413048c183e3cb556f90a878 | 2f2378acab3f444199ee2b69d2d3626f |
| answers_date_added | 2011-10-05 20:42:09 UTC+0000 | 2012-10-01 04:35:42 UTC+0000 | 2012-10-01 04:55:03 UTC+0000 | 2012-02-13 16:44:10 UTC+0000 | 2012-09-09 13:36:44 UTC+0000 |
| answers_body | <p>Basically three things: </p>\n<ol>\n<li>Big... | <html><head></head><body><p>Hi Deja,</p>\n<p>K... | <html><head></head><body><p>It looks like this... | <p><em>[Posted on behalf of a CareerVillage Pr... | <p>Yes, early in your career, employers certai... |
1 | before = pa.iloc[0]['answers_body'][:496] |
"<p>Basically three things: </p>\n<ol>\n<li>Big brand name employers or schools</li>\n<li>Academic performance (GPA)</li>\n<li>Evidence of leadership and people management skills</li>\n</ol>\n<p><strong>1) Big Brand Name Employers or Schools</strong><br>\nIf you're an Associate making $150,o00 – $200,000 USD per year, your employer is probably billing you out to clients at $600,000 USD/year. That's $50,000 USD/month. The client is going to want to know what and who they are getting for that kind of"
What a messy answers_body! Let’s clean it up by stripping html, remove punctuations and stopwords. Credits to Matteo Tosi for his regex pattern. Let’s go!
1 | uri_re = r'(?i)\b((?:https?://|www\d{0,3}[.]|[a-z0-9.\-]+[.][a-z]{2,4}/)(?:[^\s()<>]+|\(([^\s()<>]+|(\([^\s()<>]+\)))*\))+(?:\(([^\s()<>]+|(\([^\s()<>]+\)))*\)|[^\s`!()\[\]{};:\'".,<>?«»“”‘’]))' |
The following block of code basically strips html, replace punctuations, convert all string to lowercase and remove stopwords!
1 | pa['answers_body'] = pa['answers_body'].apply(strip_html) |
1 | after = pa.iloc[0]['answers_body'][:496] |
'p basically three things p ol li big brand name employers schools li li academic performance gpa li li evidence leadership people management skills li ol p strong 1 big brand name employers schools strong br associate making 150 o00 200 000 usd per year employer probably billing clients 600 000 usd year 50 000 usd month client going want know getting kind money answer john jane doe bs dartmouth md yale mba harvard clients respond oh wow impressive comment makes easier get new clients say yes'
Comparing before and after, we did a grea job!
1 | all_a = pa['answers_body'] |
(-0.5, 1439.5, 1079.5, -0.5)

Exploring tags
Let’s explore the tags by first merging the tags with tag_questions and then merge the tag of each question to our questions_answers_professionals and remove some not so useful features.
1 | ttq = merging(tags, tag_questions, "tags_tag_id", "tag_questions_tag_id") |
1 | tqq_list = ttq['tag_questions_question_id'].tolist() |
(23931, 643)
Out of the 23,931 questions, 643 questions do not have tags.
What are some common and rare tags?
1 | qttq.head().T |
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| questions_id | 332a511f1569444485cf7a7a556a5e54 | 332a511f1569444485cf7a7a556a5e54 | 332a511f1569444485cf7a7a556a5e54 | eb80205482e4424cad8f16bc25aa2d9c | eb80205482e4424cad8f16bc25aa2d9c |
| questions_author_id | 8f6f374ffd834d258ab69d376dd998f5 | 8f6f374ffd834d258ab69d376dd998f5 | 8f6f374ffd834d258ab69d376dd998f5 | acccbda28edd4362ab03fb8b6fd2d67b | acccbda28edd4362ab03fb8b6fd2d67b |
| questions_date_added | 2016-04-26 11:14:26 UTC+0000 | 2016-04-26 11:14:26 UTC+0000 | 2016-04-26 11:14:26 UTC+0000 | 2016-05-20 16:48:25 UTC+0000 | 2016-05-20 16:48:25 UTC+0000 |
| questions_title | Teacher career question | Teacher career question | Teacher career question | I want to become an army officer. What can I d... | I want to become an army officer. What can I d... |
| questions_body | What is a maths teacher? what is a ma... | What is a maths teacher? what is a ma... | What is a maths teacher? what is a ma... | I am Priyanka from Bangalore . Now am in 10th ... | I am Priyanka from Bangalore . Now am in 10th ... |
| tags_tag_id | 27490 | 21438 | 14147 | 27 | 18016 |
| tags_tag_name | college | professor | lecture | military | army |
| tag_questions_tag_id | 27490 | 21438 | 14147 | 27 | 18016 |
| tag_questions_question_id | 332a511f1569444485cf7a7a556a5e54 | 332a511f1569444485cf7a7a556a5e54 | 332a511f1569444485cf7a7a556a5e54 | eb80205482e4424cad8f16bc25aa2d9c | eb80205482e4424cad8f16bc25aa2d9c |
1 | val_cnt = ttq['tags_tag_name'].value_counts() |
Top 10 most popular tags:
college 3744
career 1566
medicine 1324
engineering 1083
business 989
doctor 946
college-major 783
science 701
nursing 692
psychology 679
Name: tags_tag_name, dtype: int64
Number of unique tags: 7091
Number of tags that occur 5 times and below: 5659
1 | top_10_val_cnt = val_cnt[:10] |
1 | def search_pat(pat, tags_list): |
1 | tags_list = val_cnt.index.tolist() |
1 | fig = { |
1 | ss = search_pat("college", tags_list) |
1 | def multi_single_tags(df, tag): |
1 | def remove_multiple(df, tag, ids_multiple, ids_single): |
1 | college_ids_multiple, college_ids_single = multi_single_tags(ttq, "college") |
1 | def combine_tags(df): |
1 | combine_qttq = combine_tags(qttq) |
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| questions_id | 332a511f1569444485cf7a7a556a5e54 | eb80205482e4424cad8f16bc25aa2d9c | 4ec31632938a40b98909416bdd0decff | 2f6a9a99d9b24e5baa50d40d0ba50a75 | 5af8880460c141dbb02971a1a8369529 |
| questions_author_id | 8f6f374ffd834d258ab69d376dd998f5 | acccbda28edd4362ab03fb8b6fd2d67b | f2c179a563024ccc927399ce529094b5 | 2c30ffba444e40eabb4583b55233a5a4 | aa9eb1a2ab184ebbb00dc01ab663428a |
| questions_date_added | 2016-04-26 11:14:26 UTC+0000 | 2016-05-20 16:48:25 UTC+0000 | 2017-02-08 19:13:38 UTC+0000 | 2017-09-01 14:05:32 UTC+0000 | 2017-09-01 02:36:54 UTC+0000 |
| questions_title | Teacher career question | I want to become an army officer. What can I d... | Will going abroad for your first job increase ... | To become a specialist in business management... | Are there any scholarships out there for stude... |
| questions_body | What is a maths teacher? what is a ma... | I am Priyanka from Bangalore . Now am in 10th ... | I'm planning on going abroad for my first job.... | i hear business management is a hard way to ge... | I'm trying to find scholarships for first year... |
| tags_tag_name | professor, lecture | military, army | working-abroad, overseas | business, networking | scholarships, firstgeneration, highschoolsenior |
1 | # qapttq = merging(qap, ttq, "questions_id", "tag_questions_question_id") |
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| answers_id | 4e5f01128cae4f6d8fd697cec5dca60c | ada720538c014e9b8a6dceed09385ee3 | eaa66ef919bc408ab5296237440e323f | 1a6b3749d391486c9e371fbd1e605014 | 5229c514000446d582050f89ebd4e184 |
| answers_author_id | 36ff3b3666df400f956f8335cf53e09e | 2aa47af241bf42a4b874c453f0381bd4 | cbd8f30613a849bf918aed5c010340be | 7e72a630c303442ba92ff00e8ea451df | 17802d94699140b0a0d2995f30c034c6 |
| answers_question_id | 332a511f1569444485cf7a7a556a5e54 | eb80205482e4424cad8f16bc25aa2d9c | eb80205482e4424cad8f16bc25aa2d9c | 4ec31632938a40b98909416bdd0decff | 2f6a9a99d9b24e5baa50d40d0ba50a75 |
| answers_date_added | 2016-04-29 19:40:14 UTC+0000 | 2018-05-01 14:19:08 UTC+0000 | 2018-05-02 02:41:02 UTC+0000 | 2017-05-10 19:00:47 UTC+0000 | 2017-10-13 22:07:33 UTC+0000 |
| answers_body | <p>Hi!</p>\n<p>You are asking a very interesti... | <p>Hi. I joined the Army after I attended coll... | <p>Dear Priyanka,</p><p>Greetings! I have answ... | <p>I work for a global company who values high... | I agree with Denise. Every single job I've had... |
| questions_id | 332a511f1569444485cf7a7a556a5e54 | eb80205482e4424cad8f16bc25aa2d9c | eb80205482e4424cad8f16bc25aa2d9c | 4ec31632938a40b98909416bdd0decff | 2f6a9a99d9b24e5baa50d40d0ba50a75 |
| questions_author_id | 8f6f374ffd834d258ab69d376dd998f5 | acccbda28edd4362ab03fb8b6fd2d67b | acccbda28edd4362ab03fb8b6fd2d67b | f2c179a563024ccc927399ce529094b5 | 2c30ffba444e40eabb4583b55233a5a4 |
| questions_date_added | 2016-04-26 11:14:26 UTC+0000 | 2016-05-20 16:48:25 UTC+0000 | 2016-05-20 16:48:25 UTC+0000 | 2017-02-08 19:13:38 UTC+0000 | 2017-09-01 14:05:32 UTC+0000 |
| questions_title | Teacher career question | I want to become an army officer. What can I d... | I want to become an army officer. What can I d... | Will going abroad for your first job increase ... | To become a specialist in business management... |
| questions_body | What is a maths teacher? what is a ma... | I am Priyanka from Bangalore . Now am in 10th ... | I am Priyanka from Bangalore . Now am in 10th ... | I'm planning on going abroad for my first job.... | i hear business management is a hard way to ge... |
| tags_tag_name | professor, lecture | military, army | military, army | working-abroad, overseas | business, networking |
1 | qapttq.shape[0], combine_qttq.shape[0] |
(49437, 23288)
We are now left with 23,242 unique questions and 49,323 rows - indicating some questions receive multiple answers.
Questions
Let’s explore the questions body by looking at the most common bigrams. Here, I remove some “noise” that are common words, polite expressions, and others deem as unhelpful.
1 | noise = ['school','would','like', 'want', 'dont', |
1 | def another_process_text(df, col): |
1 | df = another_process_text(questions, 'questions_body') |
1 | df['bigrams'] = df['questions_body'].apply(lambda x : generate_ngrams(x.split(), 2)) |
1 | all_bigrams = [] |
1 | fig, axes = plt.subplots(figsize=(15,10)) |
[Text(0,0.5,'Most frequent bigrams'), Text(0.5,0,'Frequency')]
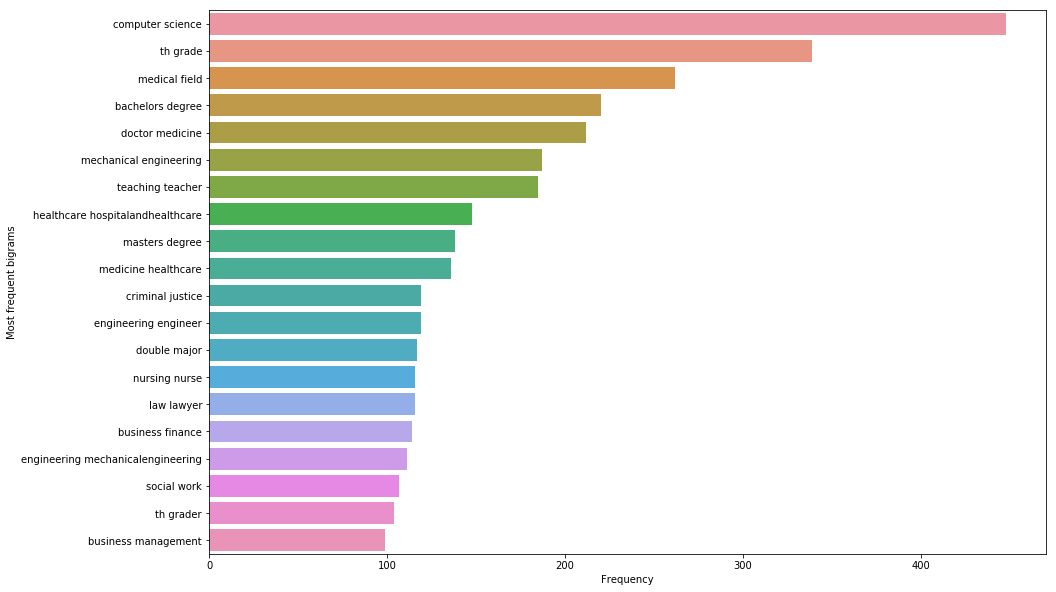
Building tag_chart
The below function takes in a tag and returns the professionals who have answered the most questions in the tag category.
1 | def tag_chart(df, what_tag, top): |
1 | # remerge our qapttq since we modified the tags in the previous one |
( answers_author_id tag_count
0 36ff3b3666df400f956f8335cf53e09e 693
1 05ab77d4c6a141b999044ebbf5415b0d 171
2 58fa5e95fe9e480a9349bbb1d7faaddb 115
3 be5d23056fcb4f1287c823beec5291e1 111
4 a1006e6a58a0447592e2435caa230f78 70,
answers_author_id tag_count
0 c3b4e11154f74a858779be7ba9b6f00c 194
1 36ff3b3666df400f956f8335cf53e09e 151
2 81a594b683d54e6dbb4b04ea00a5e25b 118
3 58fa5e95fe9e480a9349bbb1d7faaddb 58
4 e2b4c84bf1ca4aea9b108869692d8017 51)
Hero “36ff3b3666df400f956f8335cf53e09e” has answered a total of 693 questions under the tag “college” while hero “c3b4e11154f74a858779be7ba9b6f00c” has answered a total of 194 questions under the tag “engineering”.
Content Based Recommender
Ideally, we would like to associate a question to professionals who have been actively answering similar questions.
1 | def combine_authors(df): |
1 | qa_sub = qa[['questions_title', 'questions_body', 'answers_author_id', 'questions_id']].copy() |
| questions_title | questions_body | questions_id | |
|---|---|---|---|
| 0 | What is the typical compensation range for a f... | Please tell us what the common compensation ra... | edb8c179c5d64c9cb812a59a32045f55 |
| 3 | What do top tier consulting firms look for in ... | Please explain the factors consulting firms lo... | f6b9ca94aed04ba28256492708e74f60 |
| 8 | What are the top tier management consulting fi... | Which companies are the top-tier? #consulting | 4b995e60b99d4ee18346e893e007cb8f |
| 15 | What is the entry-level salary at a consulting... | I'm interested in getting benchmarks on salari... | dd363c09e4744c4b977499f215289b35 |
| 20 | What is the path to get from high school to be... | What are some of the paths to getting from beg... | ca209b4e19064d8e9834b3ca1a3f5361 |
1 | # hacky way to remove authors who are not linked |
1 | qa_cbr = process_text(qa_cbr, "questions_title") |
| questions_title | questions_body | questions_id | |
|---|---|---|---|
| 0 | typical compensation range firstyear investmen... | please tell us common compensation range compo... | edb8c179c5d64c9cb812a59a32045f55 |
| 3 | top tier consulting firms look resumes | please explain factors consulting firms look r... | f6b9ca94aed04ba28256492708e74f60 |
| 8 | top tier management consulting firms | companies toptier consulting | 4b995e60b99d4ee18346e893e007cb8f |
| 15 | entrylevel salary consulting company | im interested getting benchmarks salaries univ... | dd363c09e4744c4b977499f215289b35 |
| 20 | path get high school becoming judge | paths getting beginning high school becoming j... | ca209b4e19064d8e9834b3ca1a3f5361 |
The following recommender system was the work of Rounak Banik. A huge thanks (and credits) to Rounak!
1 | tf = TfidfVectorizer(analyzer='word', |
(23110, 27223)
1 | cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)## 输出 (23110 ,23110 ),计算questions_body 两两间的余弦相似度 |
1 | # qa_cbr = qa_cbr.reset_index() |
| questions_title | questions_body | questions_id | |
|---|---|---|---|
| 0 | typical compensation range firstyear investmen... | please tell us common compensation range compo... | edb8c179c5d64c9cb812a59a32045f55 |
| 1 | top tier consulting firms look resumes | please explain factors consulting firms look r... | f6b9ca94aed04ba28256492708e74f60 |
| 2 | top tier management consulting firms | companies toptier consulting | 4b995e60b99d4ee18346e893e007cb8f |
| 3 | entrylevel salary consulting company | im interested getting benchmarks salaries univ... | dd363c09e4744c4b977499f215289b35 |
| 4 | path get high school becoming judge | paths getting beginning high school becoming j... | ca209b4e19064d8e9834b3ca1a3f5361 |
1 | def get_recommendations_idx(title): |
1 | get_recommendations('want become army officer become army officer').head(10) |
5343 get us marines
5973 army
8452 tenth
15066 become army officer
22254 go army
13175 become army officer good become engineer
2651 us army ranger
6680 anyone provide information tes army
6864 want build career army class x
3503 way get military paid education policing educa...
Name: questions_title, dtype: object
Undeniably, they are related to army!
1 | get_questions_id('want become army officer become army officer').head(10) |
5343 4a348c16906e4ade96619f609f8d5df8
5973 552df6150cf842578f7bc7ab45ed3d05
8452 d314b89b2efa4c81ae9e7d1029ab4ee8
15066 783ff517ce5f4e76a00f78ef0ade5b75
22254 578c73c0ce8a46578d6b1f54eeb28cb9
13175 3e9b474c11654285b3e935e8b9421402
2651 73d43b7affa14b99aa1e8439e2d8bce8
6680 dbdada7ef83c4f8fae28debb7a81287d
6864 cb7c51b7f145491085b10817ae23e92b
3503 5945c9dfd5b44c43a64f390e5bc2f776
Name: questions_id, dtype: object
1 | def get_sim_authors(qids): |
1 | qids = get_questions_id('want become army officer become army officer').tolist() |
| questions_id | questions_author_id | questions_date_added | questions_title | questions_body | answers_id | answers_author_id | answers_question_id | answers_date_added | answers_body | qa_duration | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 40995 | 34ec5b3dfe824cbb92ec3b331168abbc | 0c673e046d824ec0ad0ebe012a0673e4 | 2011-12-29 04:57:02 | What is the career path to a successful career... | I'm interested in exploring a career in the mi... | ced5d4157c7744c1b751b4384c565192 | 5f77e0a2c3a144dda336df2294a64530 | 34ec5b3dfe824cbb92ec3b331168abbc | 2011-12-30 03:41:02 | <p>The opinions expressed in the comments belo... | 0 |
| 40992 | 34ec5b3dfe824cbb92ec3b331168abbc | 0c673e046d824ec0ad0ebe012a0673e4 | 2011-12-29 04:57:02 | What is the career path to a successful career... | I'm interested in exploring a career in the mi... | 538cd3dbb2a146dc86e405609d0493e0 | c7de3fcfbe384881899d1a38b0b1c532 | 34ec5b3dfe824cbb92ec3b331168abbc | 2014-12-30 19:33:15 | <p>My best advice would be to visit a recruite... | 1097 |
| 18446 | 73d43b7affa14b99aa1e8439e2d8bce8 | c81017b2723146338246f62253a16732 | 2015-10-20 18:31:03 | What should I do before being a U.S Army Ranger? | I am in 6th grade and want to be a U.S Army Ra... | 9c4ad076b63c4dd2ad26d27739281320 | 369f1c8646b649f6997eae7809696bd5 | 73d43b7affa14b99aa1e8439e2d8bce8 | 2015-10-20 20:04:06 | <p>Hi,\nYou have plenty of time but I would su... | 0 |
| 31241 | b05228bfef4940bab6eec062b64ecbc8 | 8d2c495f3e9e41228139a1a1533e3b85 | 2015-10-22 17:07:53 | How long do you have to go to school to be in ... | Because I want to serve for my country like my... | 2720403e2eb2451cbb8f4cd24492cfa9 | 36ff3b3666df400f956f8335cf53e09e | b05228bfef4940bab6eec062b64ecbc8 | 2015-10-22 21:55:08 | <p>You can go into the service after you compl... | 0 |
| 38504 | 4c6d71aaf2724b9f8d439ae086d4f3da | 8d2c495f3e9e41228139a1a1533e3b85 | 2015-10-22 17:06:12 | How do i have to go to school to in the military | Because I want to serve for my country like my... | 729ab697bbea43369cf95f25f02cdf12 | a0243e7c750e4c878fd47fe9cfb56f6f | 4c6d71aaf2724b9f8d439ae086d4f3da | 2015-11-02 20:16:18 | <p>Great question!</p>\n<p>There are a few dif... | 11 |
1 | sim_ids = [] |
| 2410 | 2520 | 4428 | 4588 | 10688 | |
|---|---|---|---|---|---|
| professionals_id | 36ff3b3666df400f956f8335cf53e09e | 36ddb593ca5742f29ed9b5ac66cf24a3 | 5c4960f30bf04d4aaf100551bb9c349f | 58fa5e95fe9e480a9349bbb1d7faaddb | 9fc88a7c3323466dbb35798264c7d497 |
| professionals_location | Cleveland, Ohio | Riverview, Florida | New York, New York | Redford Charter Township, Michigan | Lakeville, Massachusetts |
| professionals_industry | Mental Health Care | Education Management | Hospital & Health Care | Automotive | Environmental Services |
| professionals_headline | Assist with Recognizing and Developing Potential | Document Management Analyst at Bristol-Myers S... | Sense, Think, Move, movement activities for gr... | Mechanical Engineer I Automotive | Environmental Health and Safety Manager (Seeki... |
| professionals_date_joined | 2015-10-19 20:56:49 UTC+0000 | 2015-11-05 02:45:50 UTC+0000 | 2016-03-08 05:24:03 UTC+0000 | 2016-03-14 16:27:13 UTC+0000 | 2017-05-01 20:13:07 UTC+0000 |
So these are the professionals who have been answering questions related to “army”!
t-SNE visualization
Let’s explore some t-SNE visualization. Essentially, t-SNE learns a mapping from a set of high-dimensional vectors and output the outcome to a space with in 2 dimensions. Credits to DanB for sharing the t-SNE plot code.
1 | from sklearn.manifold import TSNE |
To prevent running out of memory, we sample 40% of our data for visualization purposes. Since t-SNE takes in an embedding matrix, we feed it with our tf-idf matrix.
1 | g_q_sample = qa_cbr.sample(frac=.4, random_state=43) |
array([[ 0.00266974, -0.00198474],
[-0.04657575, -0.05190464],
[ 0.00159361, 0.00021252],
...,
[-0.00081038, -0.00103935],
[ 0.00482379, 0.00101065],
[ 0.00139891, -0.00056521]], dtype=float32)
We add the x- and y-coordinate calculated by t-SNE to our dataframe.
1 | df = g_q_sample.copy() |
1 | FS = (10, 8) |
<matplotlib.collections.PathCollection at 0x1a46804400>
Seems like most points are clustered around the center region. Can we generate a better plot?
1 | FS = (18, 8) |
1 | # df |
<matplotlib.axes._subplots.AxesSubplot at 0x1a4dac5cc0>

I would say points within the .00005 region of “lifestyle pediatric surgeon” are pretty much related.
1 |