文章主要是记录个人尝试做台湾大学李宏毅教授MLDS(2017)Spring HW2-Video Caption Generation.
课程网址:http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS17.html
实现模型是S2VT(sequence to sequence:video to text),相关论文:
http://www.cs.utexas.edu/users/ml/papers/venugopalan.iccv15.pdf
这篇文章主要关注LSTM部分。CNN相关的特征直接使用了课程提供的。(Included in Dataset)
1.模型概述
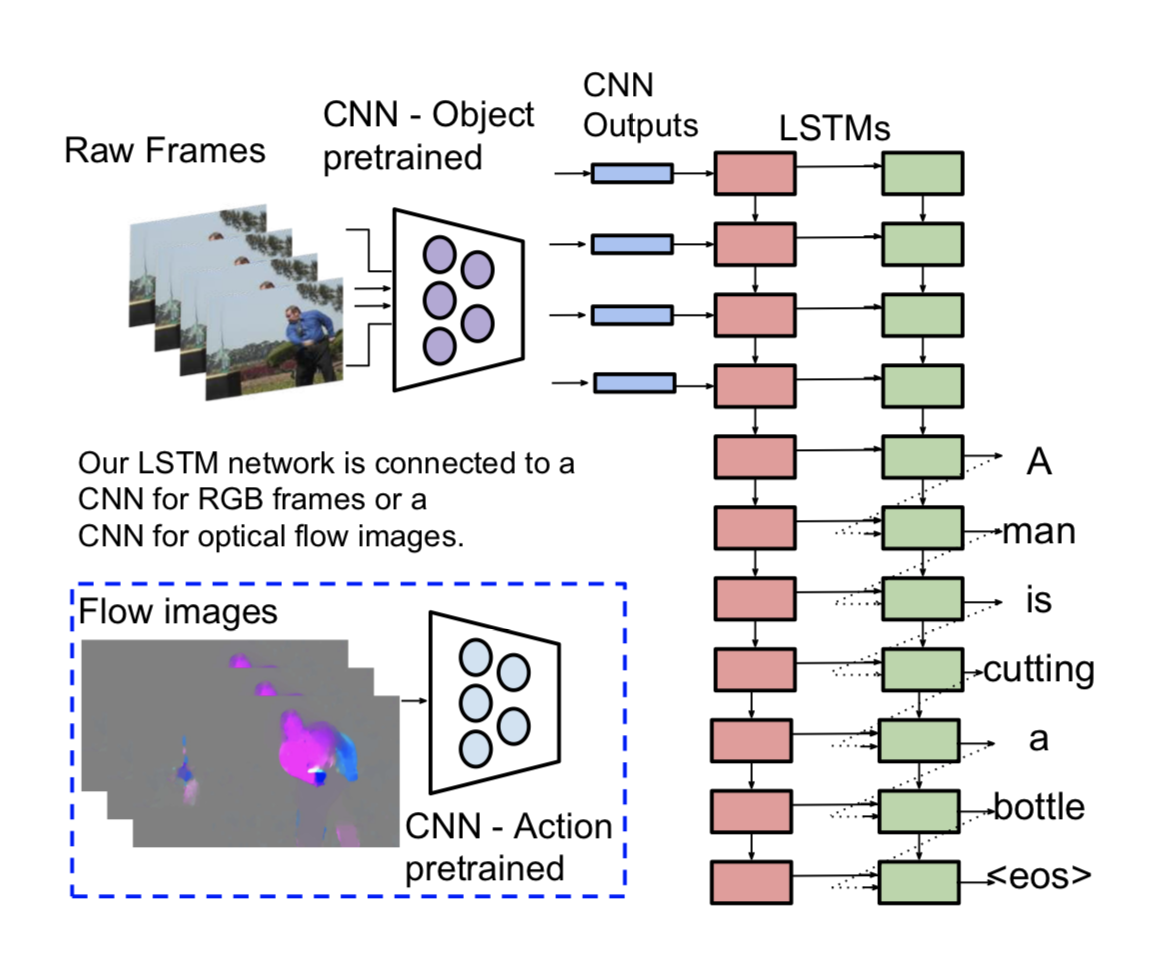
S2VT模型将通用的序列到序列模型应用到视频描述中,它包含两个LSTM网络,首先读取帧序列,然后生成一个单词序列。整个模型的有RGB图像或光学流图像两种输入烈性,都是经过CNN网络得到帧特征再作为LSTM的输入。使模型能够处理可变长度的输入帧,学习并使用视频的时序结构,以及通过学习语言模型来生成既符合语法规范又能自然表达视频内容的句子。
2.模型LSTM相关
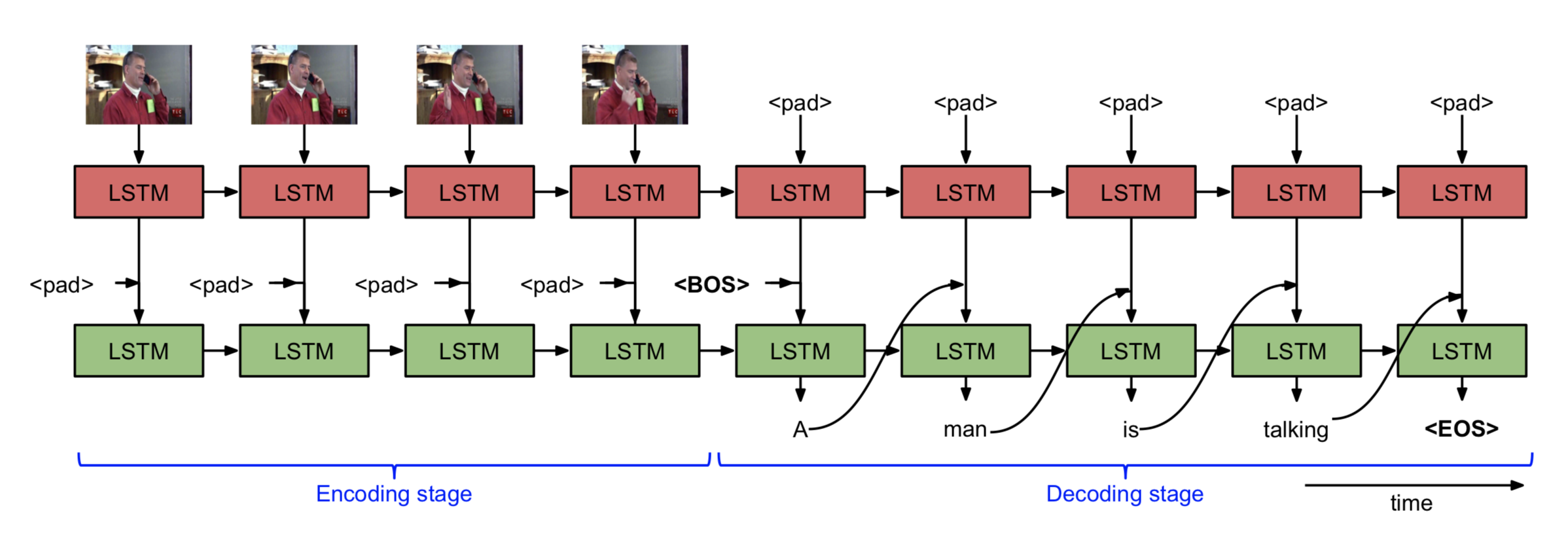
模型包括编码和解码两部分,共用一个LSTM,这是特别之处,即编码和解码过程参数共享,别问为什么,最直觉就是降低模型的复杂度~
模型具体是两层LSTM结构,接受帧序列的输入并将其解码成表述视频事件的句子。顶层的LSTM对视觉特征进行建模,第二层则建立视频序列隐藏状态表示的语言模型。
建模过程:一开始先由顶层LSTM接受帧序列并进行编码,而第二层的LSTM接受第一层的隐藏状态h,并将其与零填充符相连然后编码,这个过程不计算损失值。在所有帧都输出隐含状态后,第二层LSTM送入起始符
第二层LSTM的输出z通过在词汇库V中寻找最大可能性的目标单词y(同一般的sofemax求多分类问题),具体如下公式(2)所示:
除此,我们还需要一个明确表示句子结束的符号
3.数据集
本文使用的微软视频描述语料库-MSVD
training_data : 1450 films’s frame feature
testing_data : 50 public testing film’s frame feature
Dimension of each frame = 80*4096
training_label.json : 1450 films’s id and corresponding captions
testing_public_label.json : 50 public testing films’s id and captions
testing_id.txt : the example file will input to testing script
Download link: http://speech.ee.ntu.edu.tw/~yangchiyi/MLDS_hw2/MLDS_hw2_data.tar.gz