参考原文:https://jalammar.github.io/illustrated-transformer/
Attention机制最早应用于机器翻译的任务中,并且取得了巨大的成就,因而在最近的深度学习模型中受到了大量的关注。Transformer是一种完全基于Attention机制来加速深度学习训练过程的算法模型。Transformer在Goole的一篇论文Attention is All You Need被提出,为了方便实现调用Transformer Google还开源了一个第三方库,基于TensorFlow的Tensor2Tensor.
事实证明Transformer结构在一些特定的任务上的表现比谷歌的神经网络翻译模型还要好。然而,Transformer的最大优势在于它在并行化处理上作出的贡献。谷歌也在利用Transformer的并行化方式来营销自己的云TPU。现在,让我们来一步一步剖析Transformer模型看看它的原理。
1.扼要
首先,我们把Transformer模型当做一个黑盒,在机器翻译任务中,这个黑盒的功能就是输入一种语言然后把它翻译成其他语言。
打开黑盒,我们可以看到它由两部分组成,一个Encoders和一个Decoders。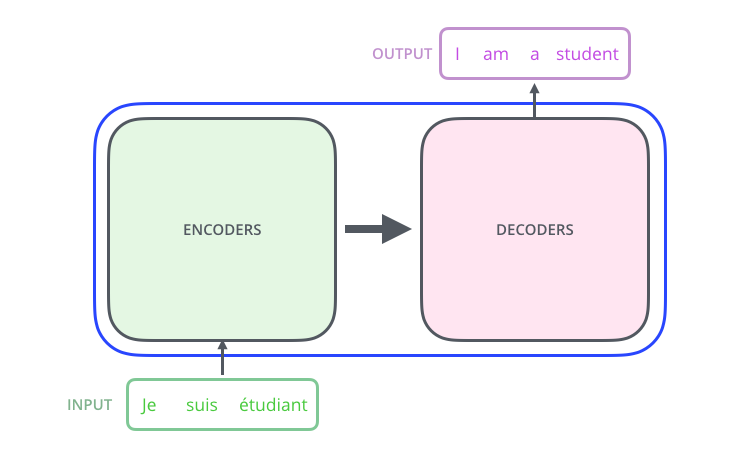
继续细看每个Encoders,它由多个Encoder堆叠而成(原论文上是6个,当然你也可以尝试其他数量的结构)。与Encoders相似,Decoders是由6个Decoder堆叠而成。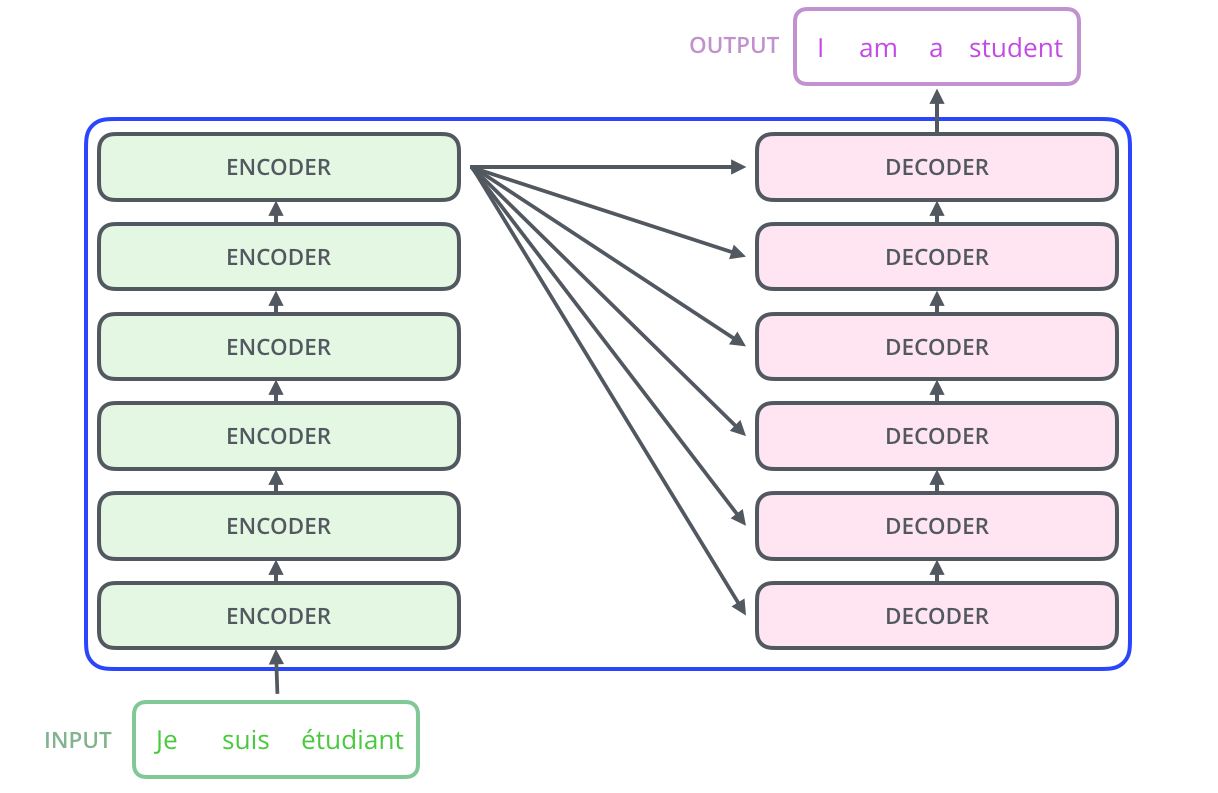
对于Encoders中的每一个Encoder,它们的结构都是一样的(但并不共享参数),都由以下两层结构组成。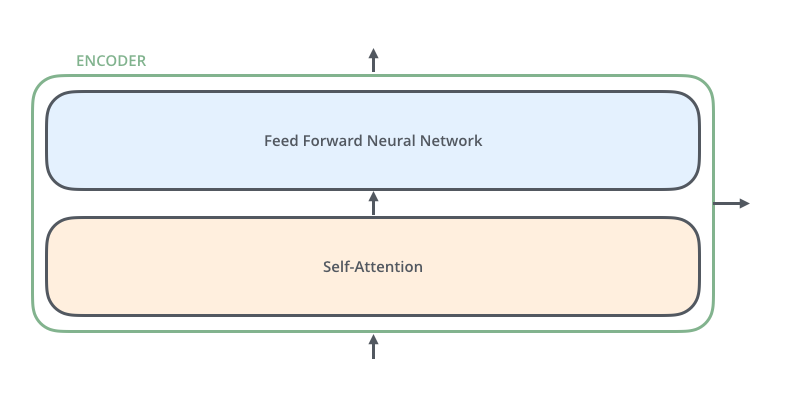
每个Encoder的输入首先会通过一个Self-Attention层,通过Self-Attention层可以使Encoder在编码单词的过程中查看输入序列的其他单词。如果不清楚这里在讲什么,没关系,下文中会详细介绍Self-Attention的。
Self-Attention的输出会被传入一个全连接的前馈神经网络,这里会把同一个前馈神经网络分别应用于每一个位置(单词)。
每个Decoder也同样具有这样的层级结构,但是在这之间有一个Attention层,帮助Decoder专注于与输入句子中对应的那个单词(类似于基于Attention 的 seq2seq models那样)。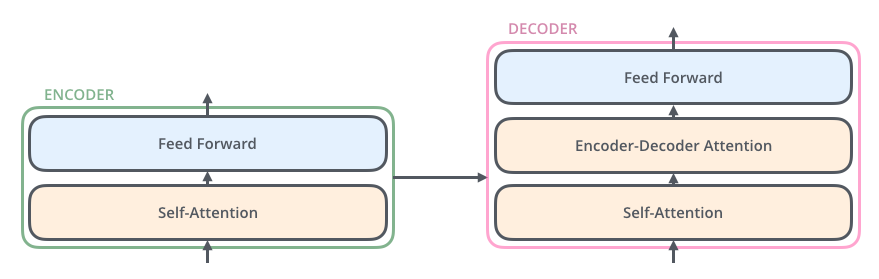
2.图解张量
到现在为止,我们已经了解了Transformer的主要结构。现在我们一图示的方法来研究Transformer模型中各种张量/向量,观察从输入到输出过程中这些数据在网络结构中的流动。
就像一般的NLP问题的处理一样,我们先把输入处理成词嵌入。
每个单词编码为512维,这些长格子图形代表一个单词的向量。词嵌入的过程只发生在最底层的Encoder。但是对于所有的Encoder来说,你都可以按下图来理解。输入(一个向量的列表,每个向量的维度为512维,在最底层Encoder的是词嵌入,其他层就是其前一层的output)。另外这个列表的大小和词向量维度的大小都是可以设置的超参数。一般情况下,列表大小是我们训练数据集中最长的句子的长度。
当我们把句子序列处理成词嵌入后,如下图,把它们输入到Encoder,流过两层结构。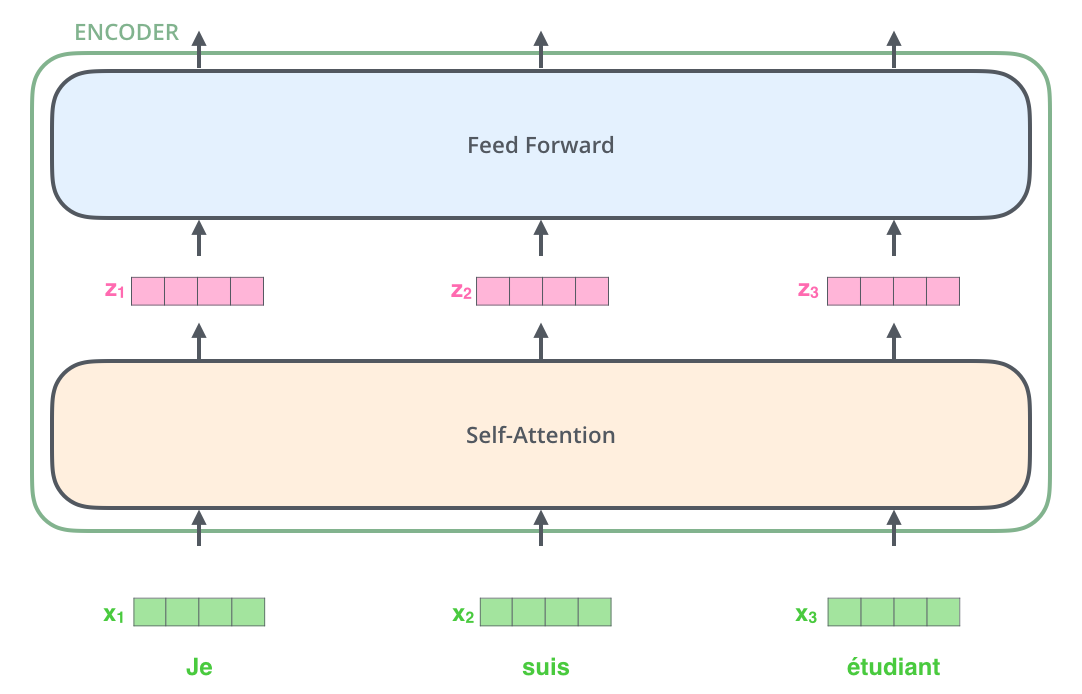
在这里,我们注意到Transformer的一个注意点,每个单词在Encoder的流动路径中,经过Self-Attention层时,这些路径之间存在依赖关系。而Feed Forward层是没有的,所以在前馈层,我们可以用到并行化来提升速率。
下面,我们用一个简短的句子来作为例子,一步一步看看Input在Encoder的每个子层中做了什么处理。
3.Now We’re Encoding!
正如前面所说,Transformer的Encoder接收一个512维度的向量的列表作为输入,然后将这些向量传递到Self-Attention层,Self-Attention层产生一个等量512维向量列表,然后进入前馈神经网络,前馈神经网络的输出也为一个512维度的列表,然后将输出向上传递到下一个Encoder。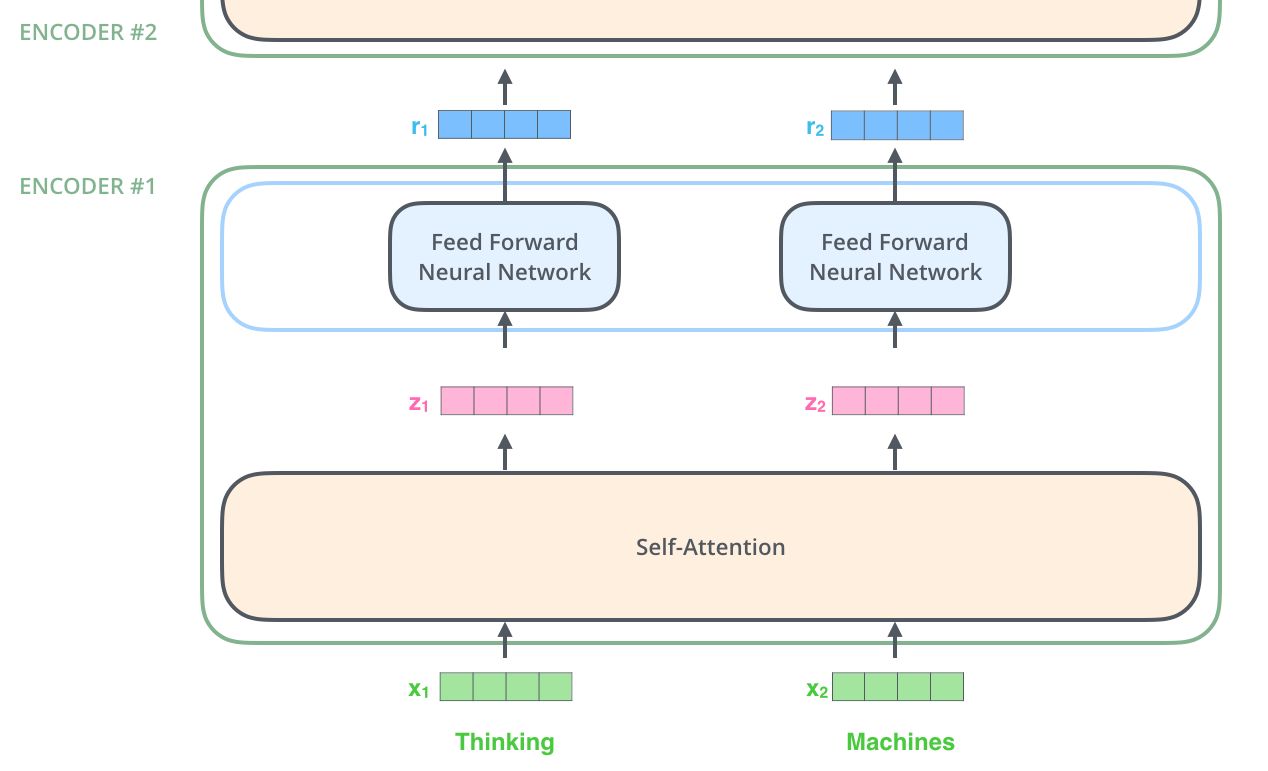
如上图所示,每个位置的单词首先会经过一个Self-Attention层,然后每个单词都分别通过同一个前馈神经网络。
4.Self-Attention at a High Level
如果你对Self-Attention不熟悉,没关系,你可以通过这篇Attention is All You Need论文来进一步了解。下面是作者对自己理解的一些提炼。
假设这就是我们需要翻译的输入句:“The animal didn’t cross the street because it was too tired”
这句话中的“it”指的是什么呢?它是指句子中的“animal”还是“street”呢?这对我们人来说是一个很简单的问题,但对算法来说,这其实不是一个很容易处理的问题。Self-Attention的出现就是为了解决这个问题,通过Self-Attention,我们能将“it”与“animal”联系起来。
当模型处理每个单词的时候,self attention可以是当前单词去查看输入句子的其他单词,以此来寻找线索更好地编码这个单词(可以理解为编码中包含了当前单词跟其他单词的关联关系)。
如果你熟悉RNNs,那么你可以回想一下,RNN是怎么通过hidden state处理先前单词(向量)与当前单词(向量)的关系的。self-attention正是transformer中设计的一种通过其上下文来理解当前词的一种办法。
如上图,是我们第五层Encoder针对单词“it”的图示,可以发现,我们的Encoder在编码单词“it”时,部分注意力机制集中在了“animal”上,这部分的注意力会通过权值传递的方式影响到“it”的编码。
更多细节可以查看Tensor2Tensor notebook.
5.Self-Attention in Detail
我们先看看如何用向量的方式来计算Self-Attention。然后再来看看它是如何通过矩阵来实现的。
计算Self Attention的第一步是对每个Encoder的输入向量列表(在这里是每个单词的embedding)创建3个向量。即针对对每个单词,创建一个Query向量,一个Key向量,一个Value向量。这些向量是通过词嵌入乘以我们训练过程中创建的3个训练参数矩阵而产生的。
注意这些新向量的维度比词嵌入向量小。我们知道嵌入向量的维度为512,而这里的新向量的维度只有64维。新向量并不是必须小一些,这是网络架构上的选择使得Multi-Headed Attention(大部分)的计算不变。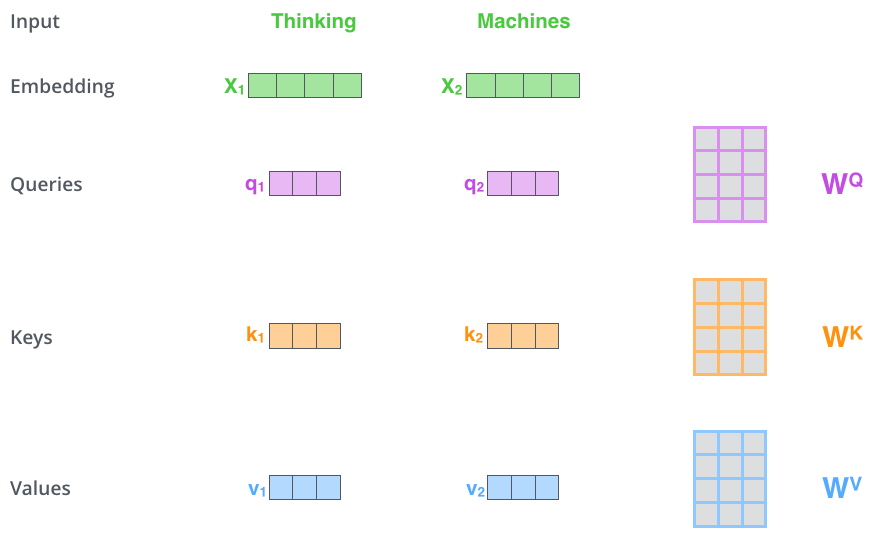
将向量x1乘以权重矩阵WQ(一个Encoder的所有输入共享一个权重矩阵),得到关于单词的Query向量q1。同理,最终我们可以对输入句子的每个单词创建“query”,“key”,“value”的新向量表示形式。
“query”,“key”,“value”是什么向量呢?有什么用呢?
- 传统注意力机制,也称为scaled Dot-Product Attention,可以看成是有一个询问的词(query),去跟一堆哈希表中的键值对(key-value pair)进行匹配,找到最相关的键(key),之后返回该键所对应的值(value)。通常的,如果我们只返回一个key所对应的value,我们称之为hard attention。如果我们对所有的key都计算一个相关系数,(也称之为attention weight),我们可以将所有key对应的value进行加权求和(weighted sum)这样的操作我们称之为soft attention。
- 这里如果$d_k$很大的时候,两个向量的乘积会变得很大,使得softmax会得到非常小的数值,所以我们会在这里除以$\sqrt{d_k}$来抵消这个影响。
这些向量的概念是很抽象,但是它确实有助于计算注意力。不过先不用纠结去理解它,后面的的内容,会帮助你理解的。
计算Self Attention的第二步是计算一个得分。以上图为例,假设我们在计算第一个单词“thinking”的self attention。我们需要根据这个单词对输入句子的每个单词进行评分。当我们在某个位置编码单词时,分数决定了对输入句子的其他单词的关注程度。
通过将query向量和key向量点积来对相应的单词打分。所以,如果我们处理#1位置的的self attention,则第一个分数为q1和k1的点积,第二个分数为q1和k2的点积(当前位置单词的query向量去和其它位置单词的key向量做点积)。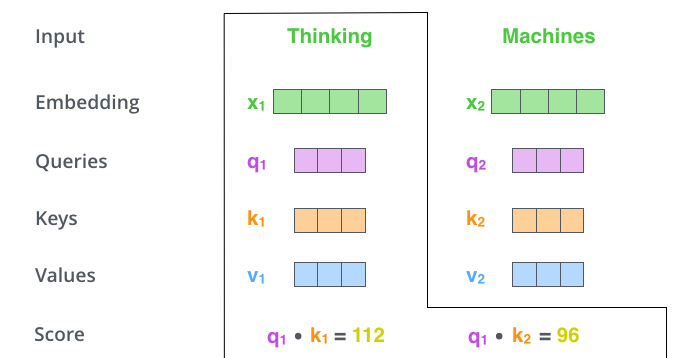
第三和第四步的计算是,将第二部得到的score分别除以8()(论文中使用key向量的维度是64维,其平方根=8,这样可以使得训练过程中具有更稳定的梯度。这个并不是唯一值,经验所得)。然后再将得到的输出通过softmax函数标准化,使得最后的列表和为1。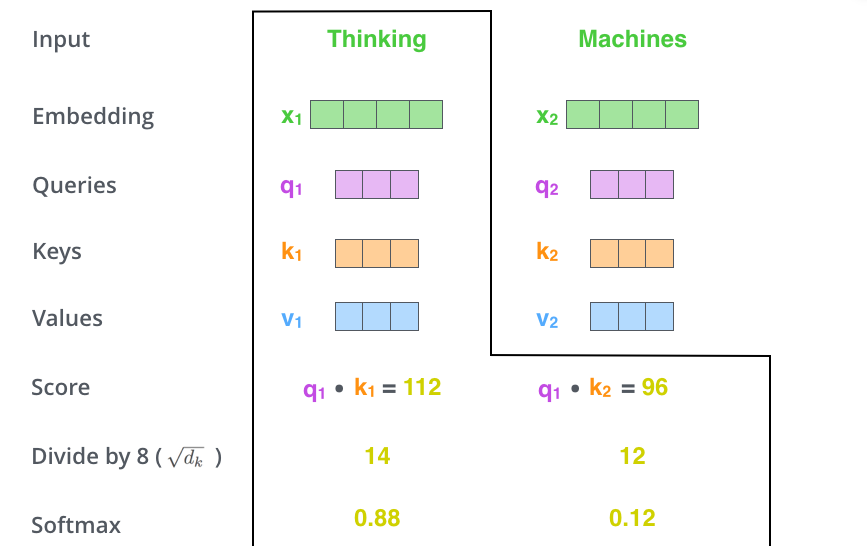
这个softmax的分数决定了当前单词在句子中每个位置单词的关注程度。很明显,当前单词对应句子中此单词所在位置的softmax的分数最高,但是,有时候attention机制也能关注到此单词外的其他单词,这很有用。
第五步是把value向量和sofemax分数(这里等于加权求和)。这里的直觉就是保留我们想要关注的单词,忽略不要关注的词(例如不关注的乘以0.001)。
第六步就是对相乘得到的向量做加权求和,得到当前位置单词的self attention层的输出。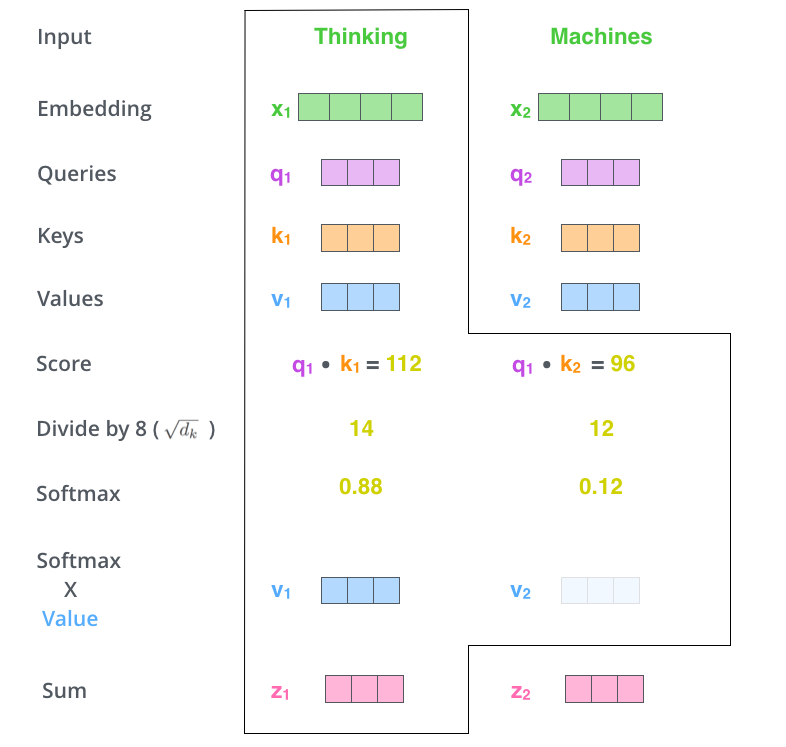
总结self-attention的计算过程,(单词级别)就是得到一个我们可以输入到前馈神经网络的向量。 然而在实际的实现过程中,该计算会以矩阵的形式完成,以便更快地处理。下面我们来看看Self-Attention的矩阵计算方式。
6.Matrix Calculation of Self-Attention
第一步是去计算query,key和value矩阵。我们将句子的词嵌入堆叠成矩阵X,并将其乘以我们训练的权重矩阵$(W^{Q},W^{K},W^{V})$。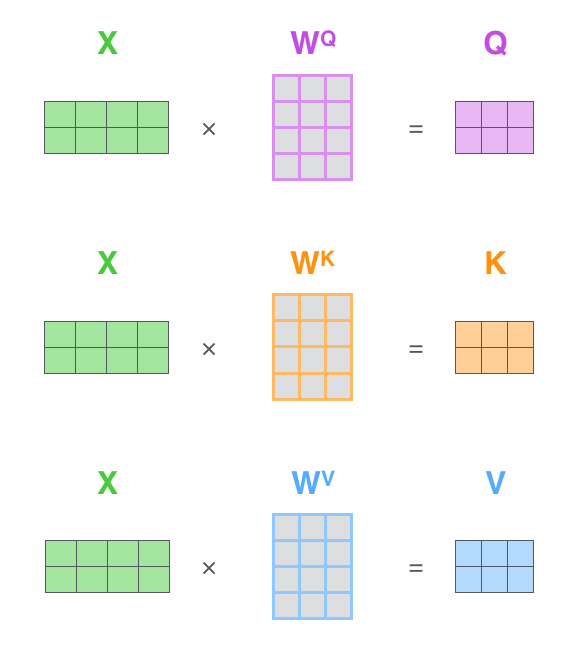
X矩阵中的每一行对应于输入句子中的一个单词。 我们看到的X每一行的方框数实际上是词嵌入的维度,图中所示的和论文中是有差距的。X(图中的4格方框代表论文中为512)和q / k / v向量(图中的3格方框代表论文中为64)。
最后,在矩阵处理方法里,我们可以把上面的第二至第六步骤的计算浓缩到以下的计算中,得到整个self-attention层的输出。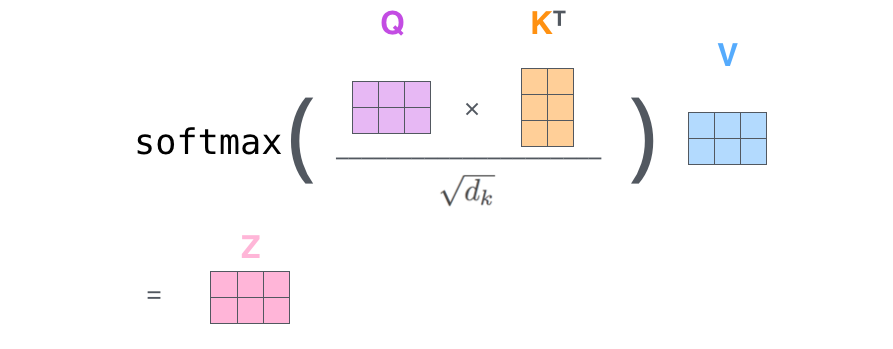
7.The Beast With Many Heads
本文通过使用“Multi-headed”的机制来进一步完善self attention层。“Multi-headed”主要通过下面两个方面改善了attention层的性能:
1.它扩展了模型关注不同位置的能力。图片中z1包含了更多自己位置的编码,较少其他位置的编码,但是在上面例子中可以看出,“The animal didn’t cross the street because it was too tired”,我们的attention机制会更加关注其它位置的编码,计算出“it”指代的为“animal”,这在对语言的理解过程中是很有用的。
2.它为attention层提供了多个“representation subspaces”由下图可以看到,在self attention中,我们有多个个Query / Key / Value权重矩阵(Transformer使用8个attention heads)。这些集合中的每个矩阵都是随机初始化生成的。然后通过训练,用于将词嵌入(或者来自较低Encoder/Decoder的向量映射到不同的“representation subspaces”(表示子空间)中。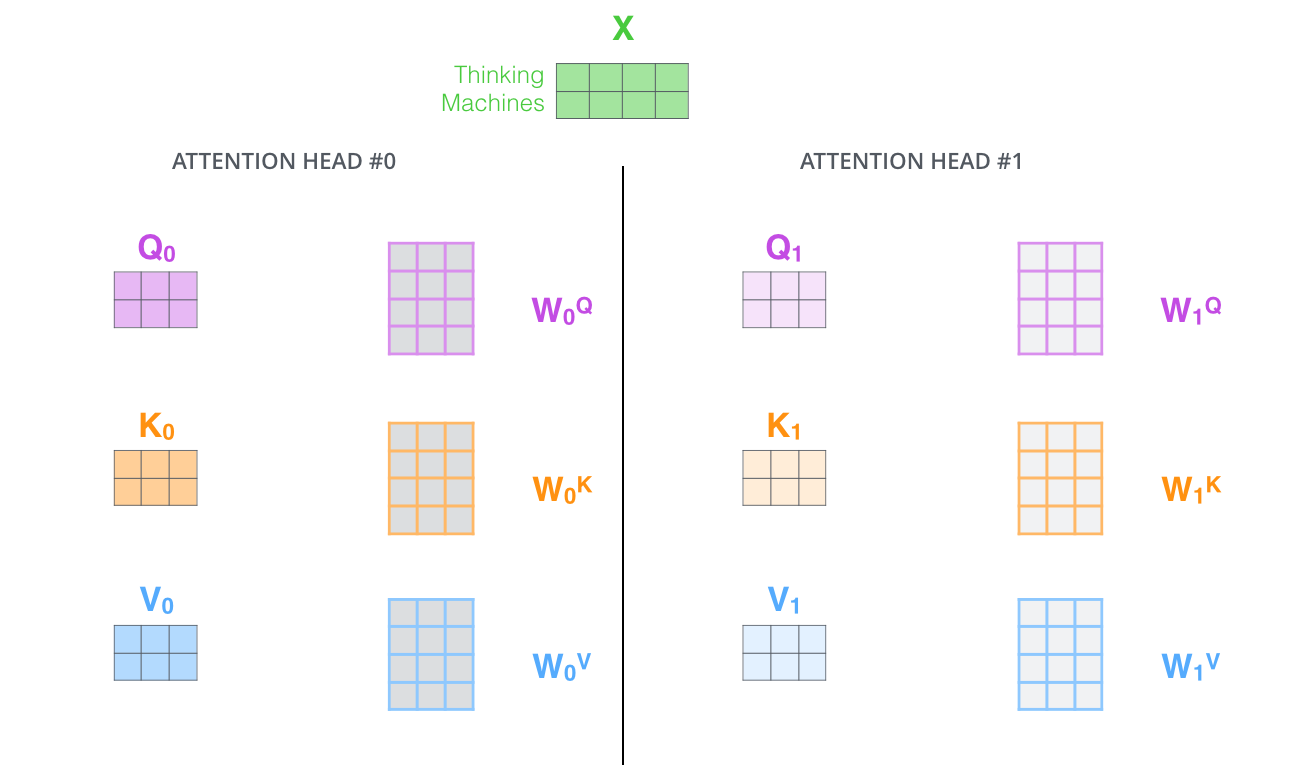
通过multi-headed attention,我们为每个“head”都独立维护一套Q/K/V的权值矩阵。然后我们还是如之前单词级别的计算过程一样处理这些数据,得到不同的Q/K/V矩阵。
如果对上面的例子做同样的self attention计算,而因为我们有8头attention,所以我们会在八个时间点去计算这些不同的权值矩阵,最后,我们会得到8个不同的Z矩阵。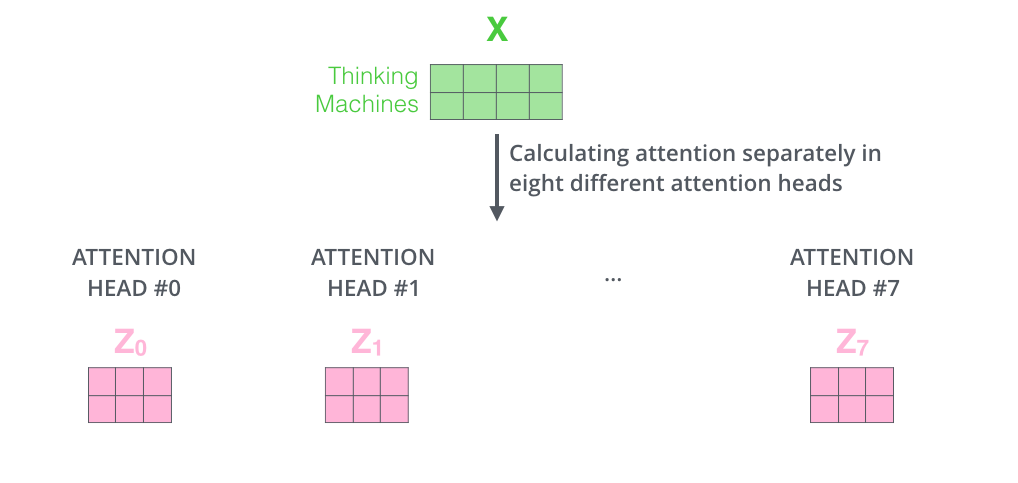
这里有个问题,我们不希望把8个矩阵输入到前馈网络层,我们希望只输入一个矩阵(一个单词用一个向量表示)。所以我们需要把这8个矩阵浓缩成一个。
处理办法就是把8个矩阵拼接起来,然后乘以一个额外的权重矩阵$W^{o}$。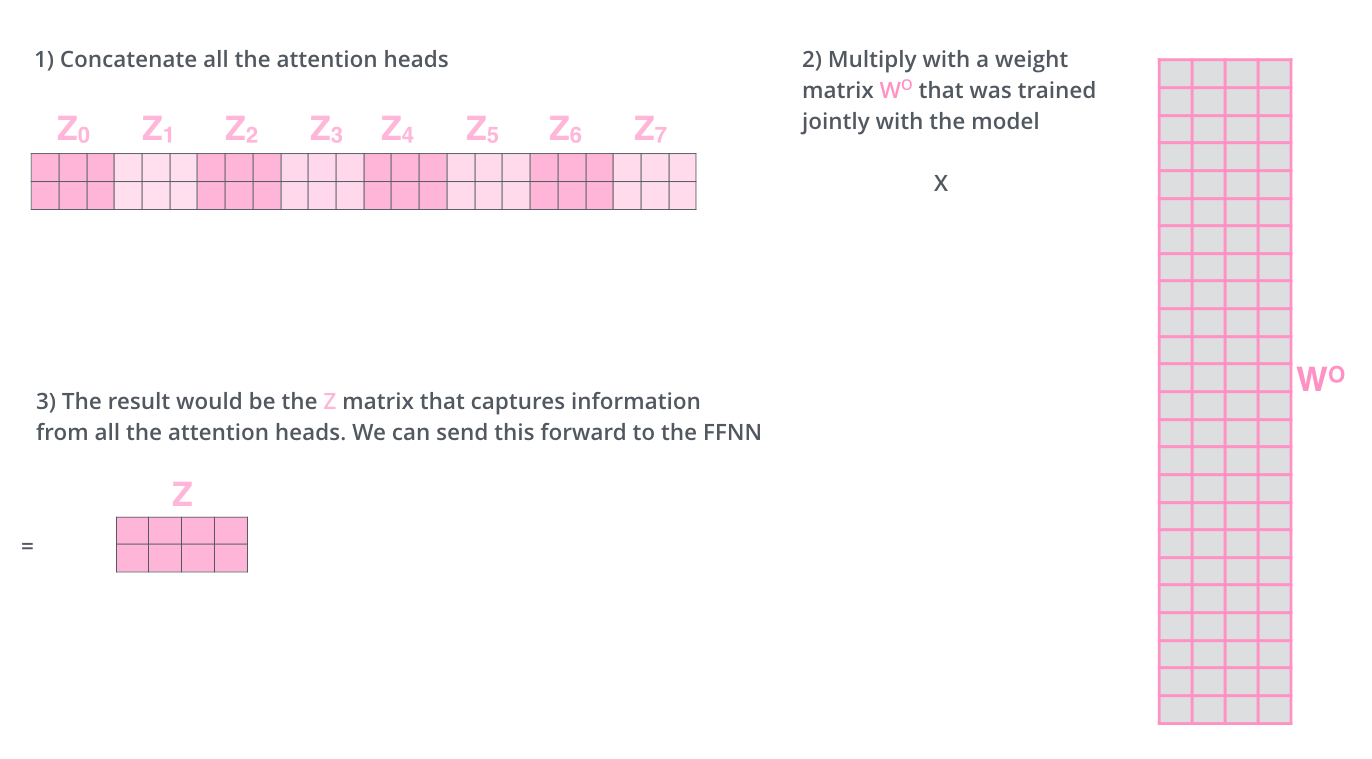
这样multi-headed self attention的全部内容就介绍完了。之前可能都是一些过程的图解,现在我将这些过程连接在一起,用一个整体的框图来表示一下计算的过程,希望可以加深理解。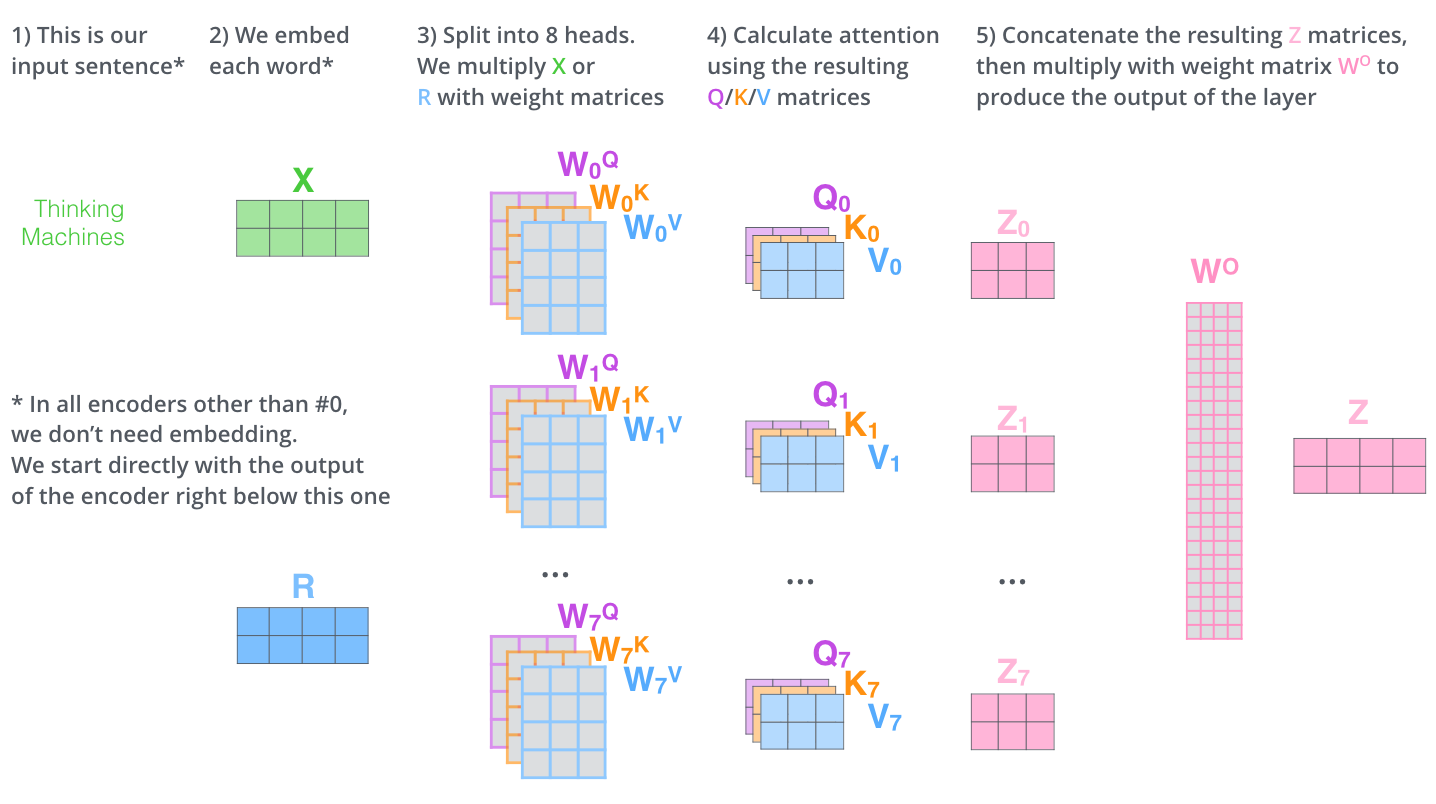
现在我们已经触及了multi-headed self attention,让我们重新审视我们之前的例子,看看例句中的“it”这个单词在不同的attention head情况下会有怎样不同的关注点:
如图:当我们对“it”这个词进行编码时,一个注意力的焦点主要集中在“animal”上,而另一个注意力集中在“tired”。
但是,如果我们将所有注意力添加到图片中,那么事情可能更难理解: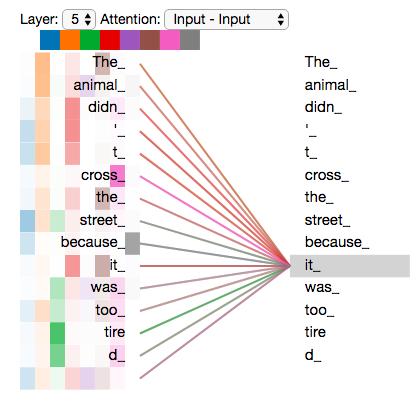
8.Representing The Order of The Sequence Using Positional Encoding
我们介绍这个模型到目前为止,忽略了一个很重要的内容,就是怎么把序列中单词的顺序考虑进来。(由于Transformer不像LSTM那样是循环序列结构。从上面的编码过程中可以看出,我们是不考虑顺序的,每个单词可以很容易跟句子中任意位置的单词进行关联,这点很好得解决了LSTM中长期记忆困难的问题,但是却丢掉了位置这个重要的信息。)
为了解决这个问题,Transformer为每个词嵌入增加加了一个向量,它可以帮助我们确定每个词的位置信息,或者序列中不同单词之间的距离信息。这些位置编码向量有固定的生成方式,所以获取它们是很方便的。直觉上讲就是,我们把这些向量加入到词向量中,然后再去获取Q/K/V向量,这样得到的attention就包含位置信息了。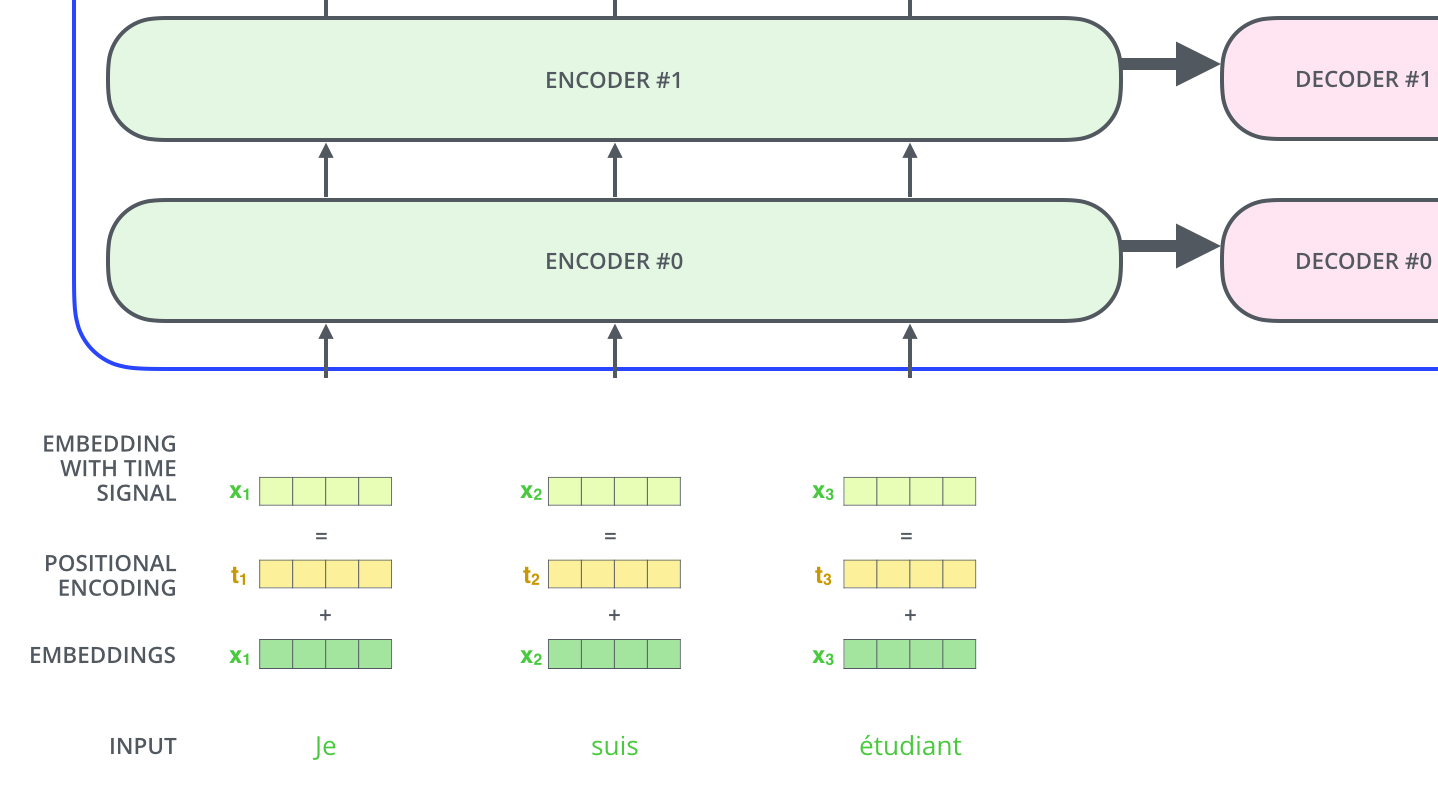
为了让模型捕捉到单词的顺序信息,我们添加位置编码向量信息(POSITIONAL ENCODING)-位置编码向量不需要训练,它有一个规则的产生方式。
假设词嵌入维度为4,那么实际上的位置编码就如下图所示: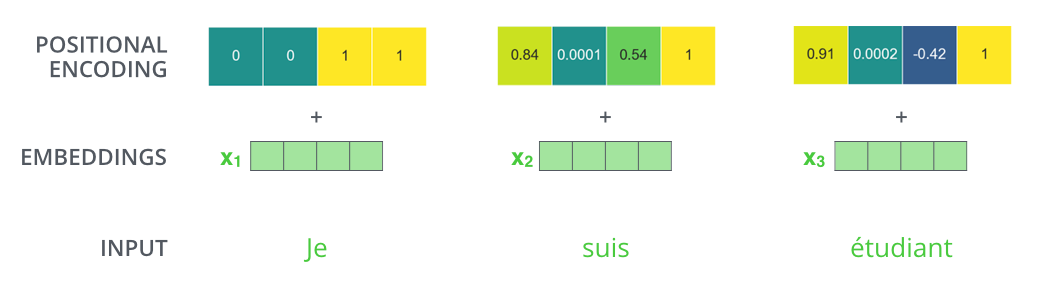
那么生成位置向量需要遵循怎样的规则呢?
观察下面的图形,每一行都代表着对一个向量的位置编码。因此第一行就是我们输入序列中第一个字的嵌入向量,每行都包含512个值,每个值介于1和-1之间。我们用颜色来表示1,-1之间的值,这样方便可视化: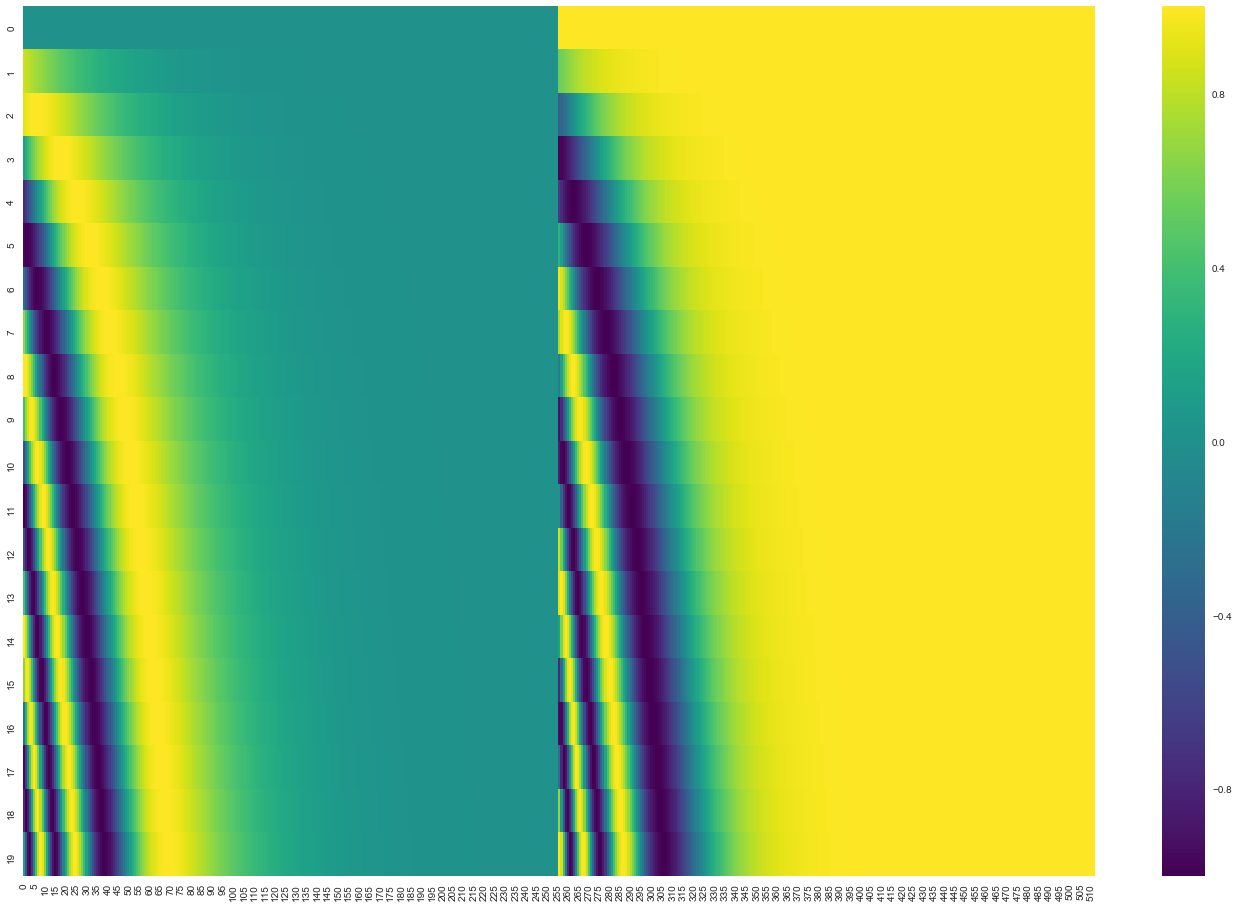
这是一个20个字(行)的(512)列位置编码示例。你会发现它咋中心位置被分为了2半,这是因为左半部分的值是一由一个正弦函数生成的,而右半部分是由另一个余弦函数生成。然后将它们连接起来形成每个位置编码矢量。
位置编码的公式在论文(3.5节)中有描述。你也可以在中查看用于生成位置编码的代码get_timing_signal_1d()。这不是位置编码的唯一可能方法。然而,它具有能够扩展为不固定的序列长度的优点(例如,如果我们训练的模型被要求翻译的句子比我们训练集中的任何句子都长)。
9.The Residuals
在模型结构中,我们还要注意一个细节。每个Encoder的子层之间,我们加了一个残差连接,和一个layer-normalization步骤。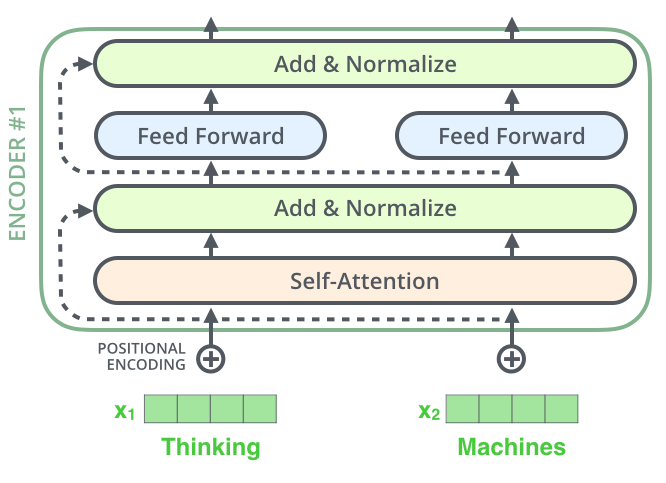
在进一步探索其内部计算方式,我们可以将上面的Add & Normalize图解成下面: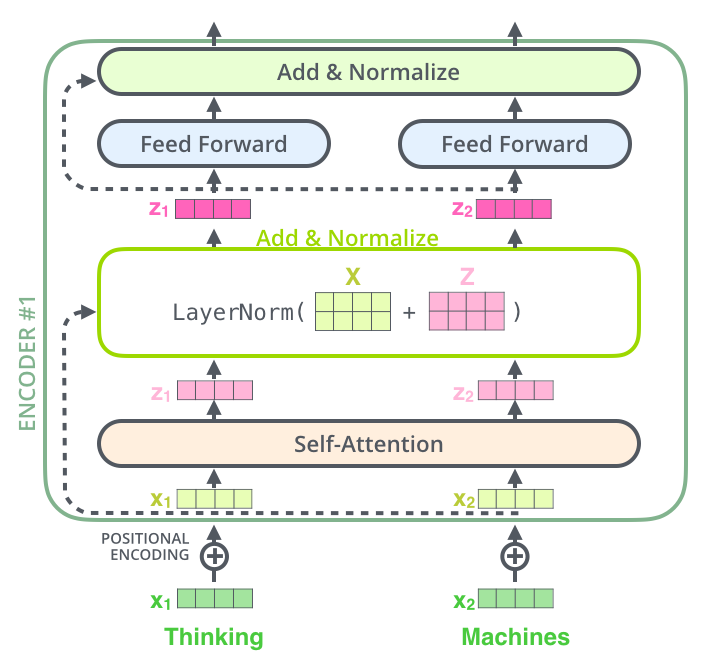
Decoder的子层也是同样的,如果我们想做堆叠了2个Encoder和2个Decoder的Transformer,那么它可视化就会如下图所示: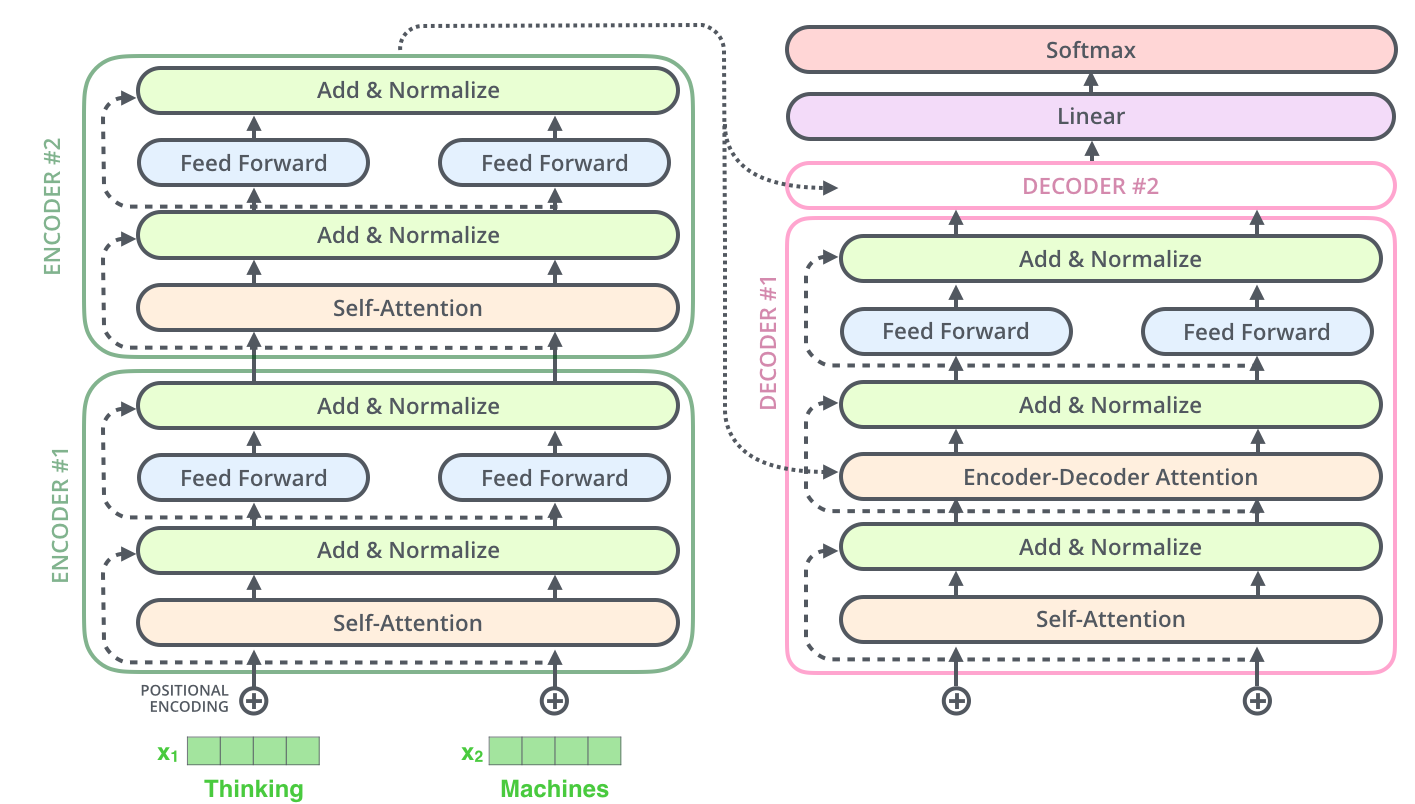
10.Feed Forward Layer
对于Encoder和Decoder的每个attention层之后,我们会连接一个全连接的前向神经网络。这个网络包含了两个线性转换和中间加一个ReLU的激活函数。
这里每一层,我们都用不同的$W_1,W_2,b_1,b_2$。
11.The Decoder Side
我们已经基本介绍完了Encoder的大多数概念,我们基本上也可以预知Decoder是怎么工作的。现在我们来仔细探讨下Decoder的数据计算原理。
当序列输入时,Encoder开始工作,最后在其顶层的Encoder输出向量组成的列表,然后我们将其转化为一组attention的集合(K,V)(这里的K,V大概和Encoder之前的query向量和key向量一样的方式获得)。(K,V)将带入每个Decoder的“encoder-decoder attention”层中去计算,这样有助于decoder关注在输入序列的相关位置上。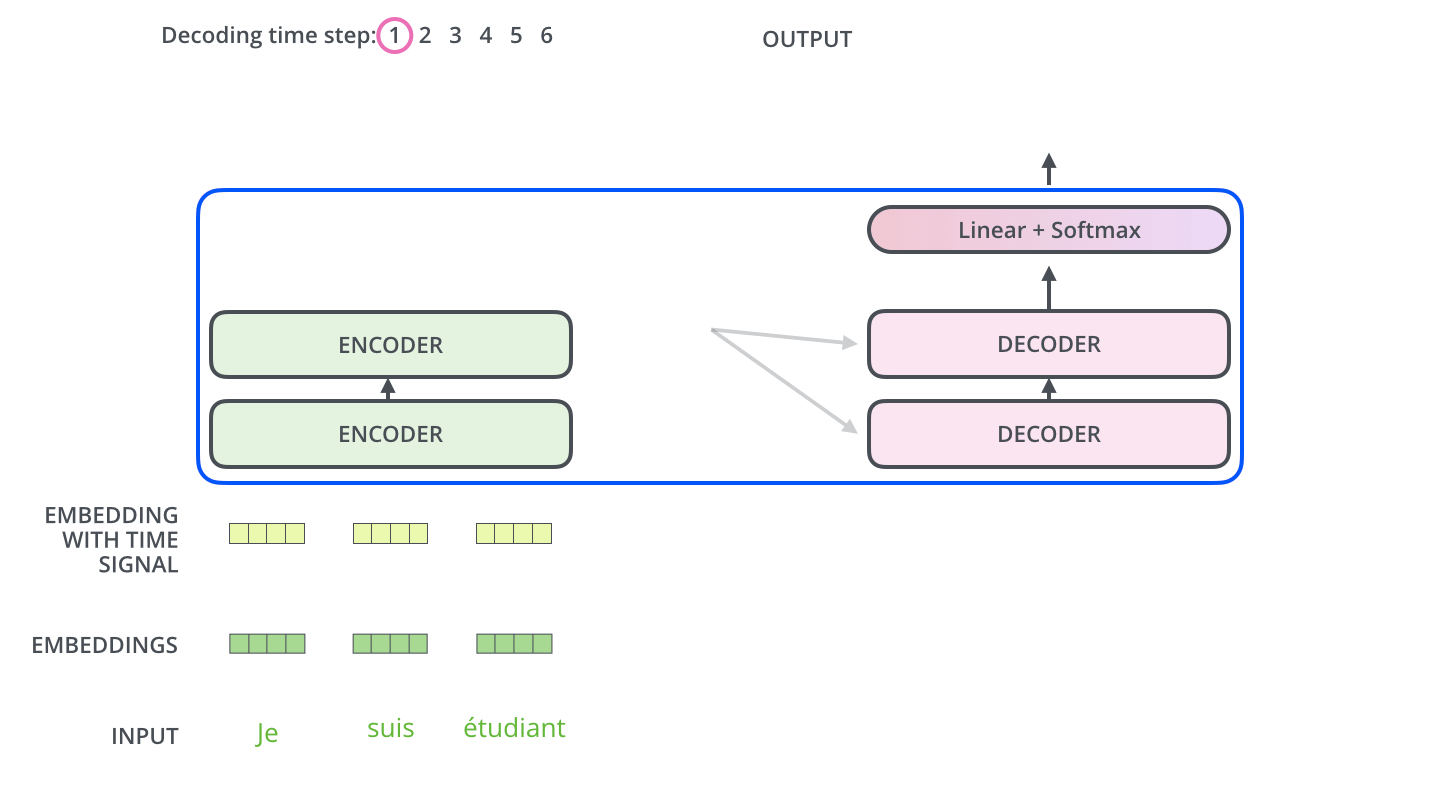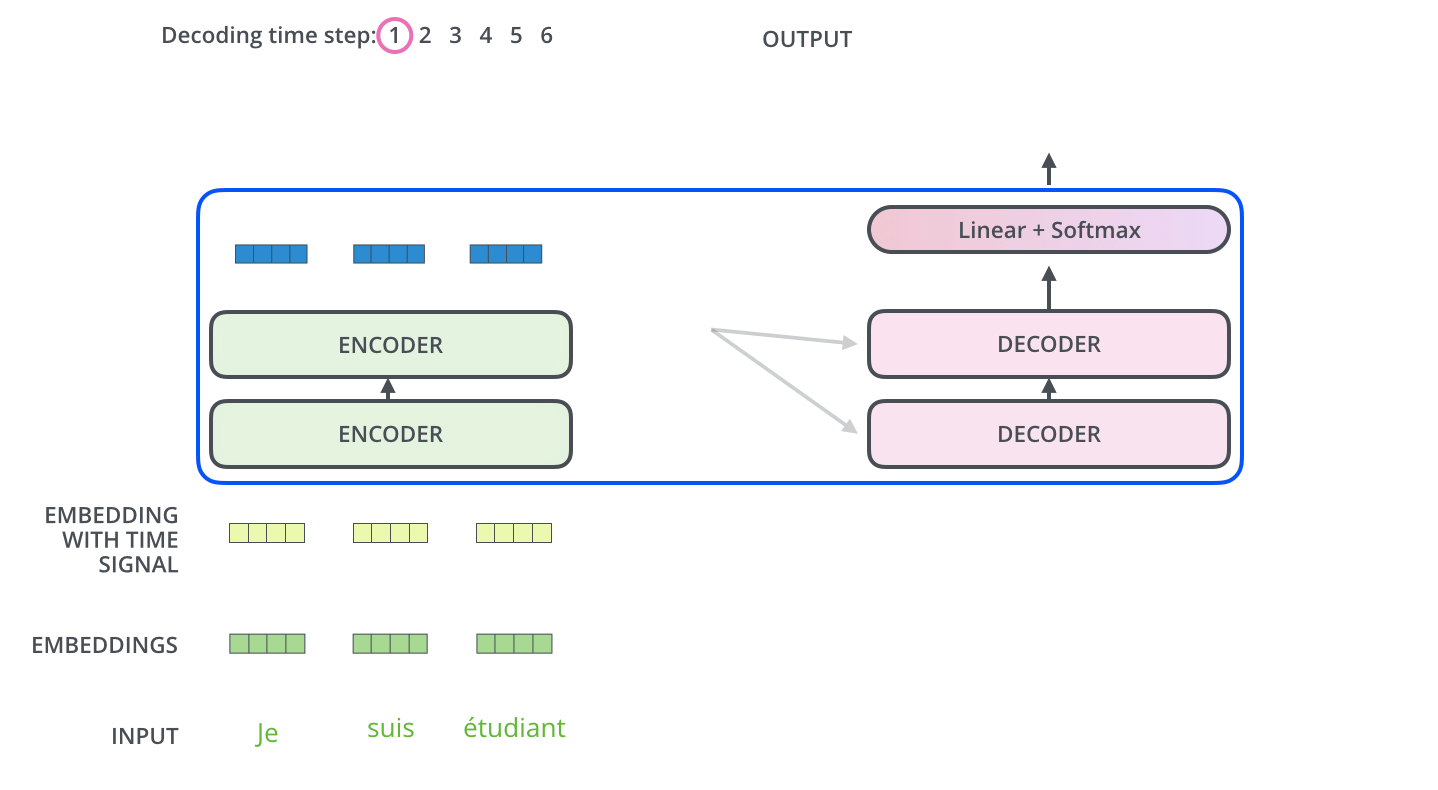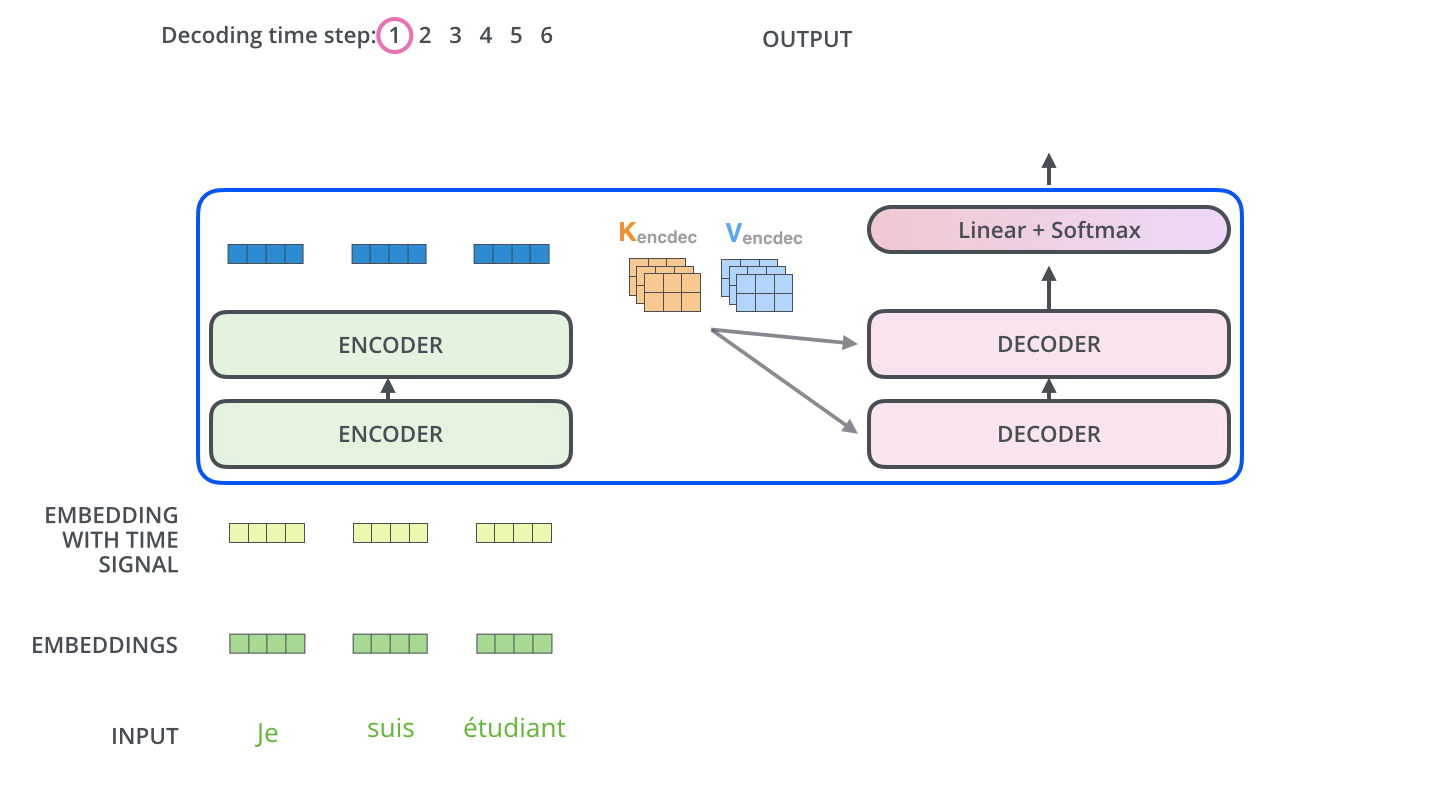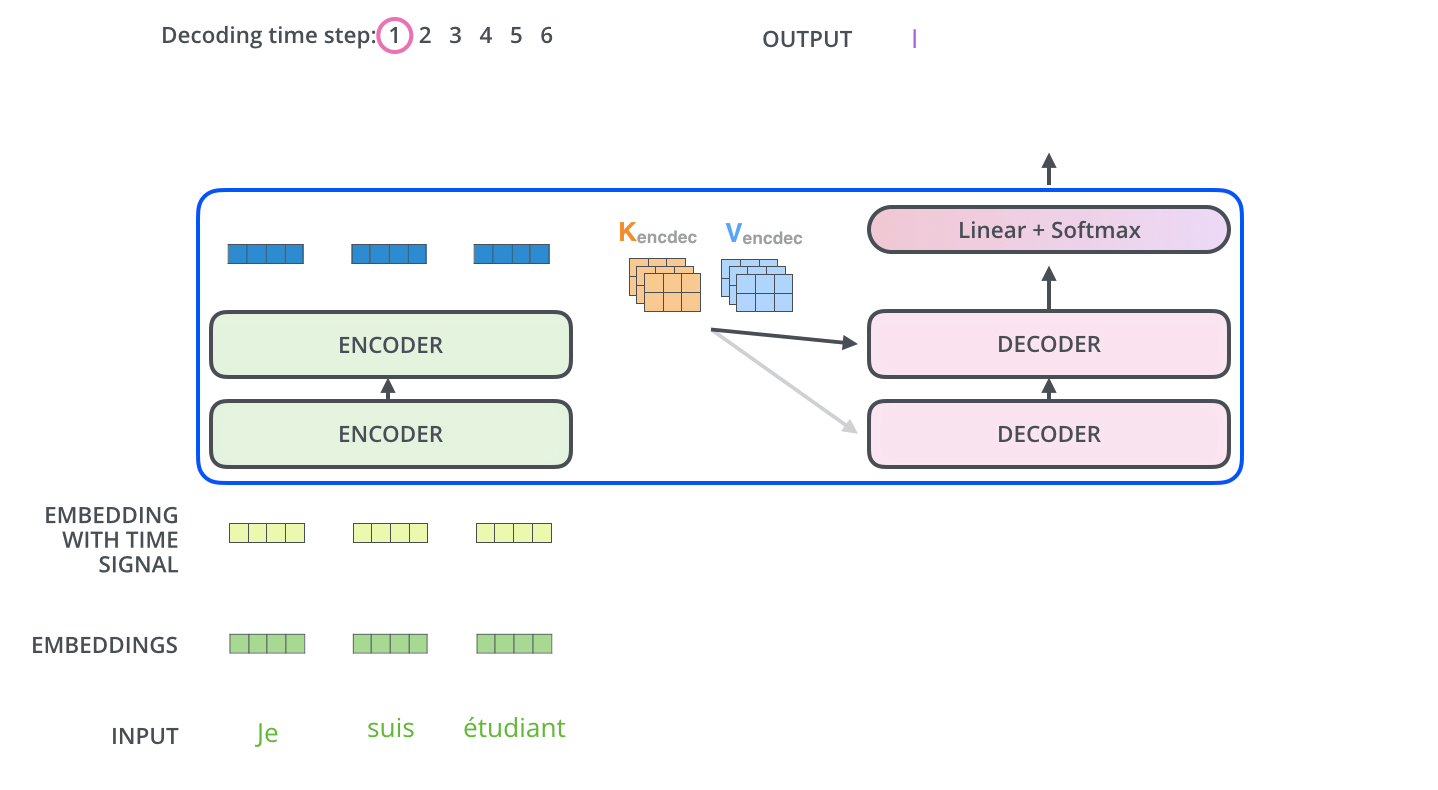
完成encoder阶段后,我们开始decoder阶段,decoder阶段中的每个步骤输出来自输出序列的元素(在这个例子中为英语翻译句子)。
我们以下图的步骤进行训练,直到输出一个特殊的符号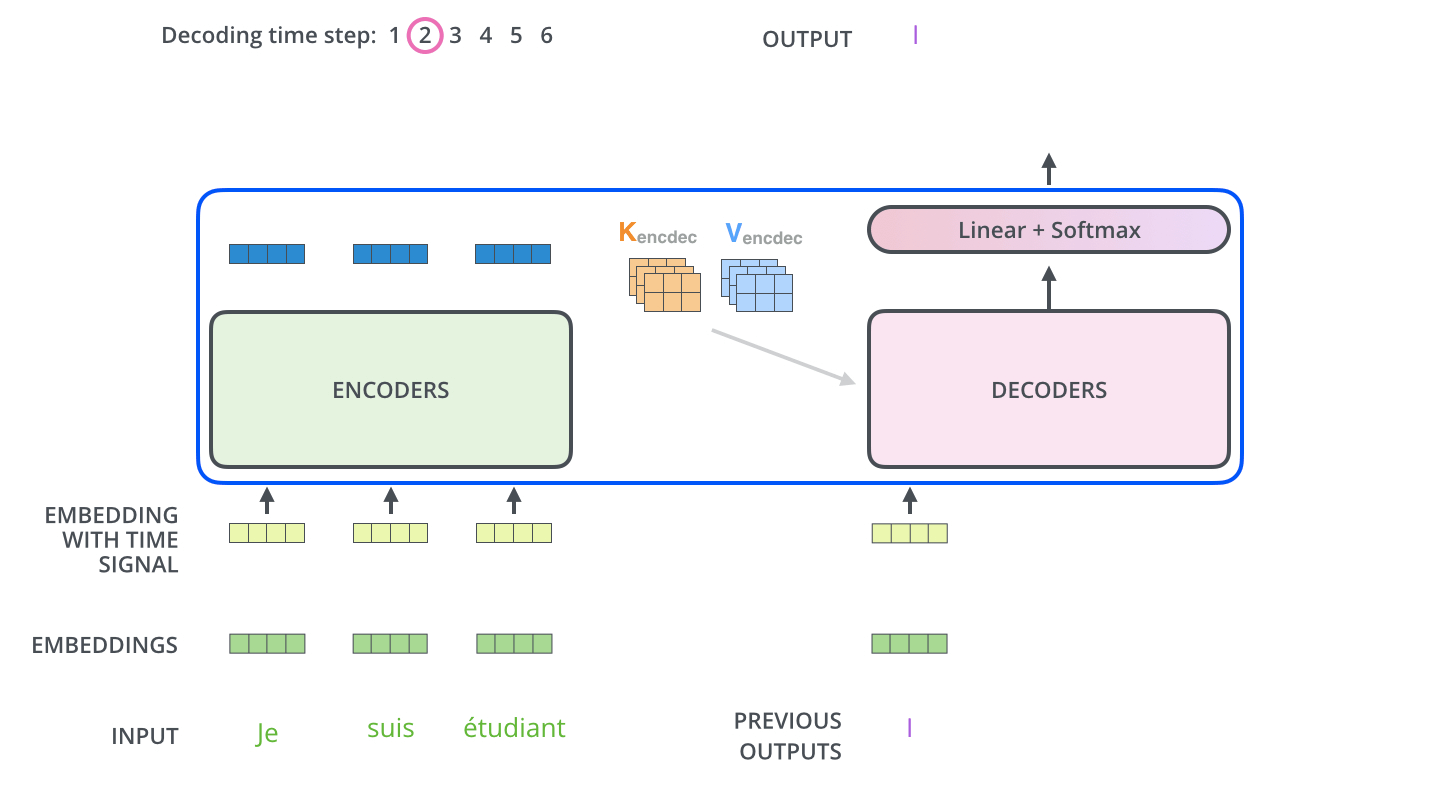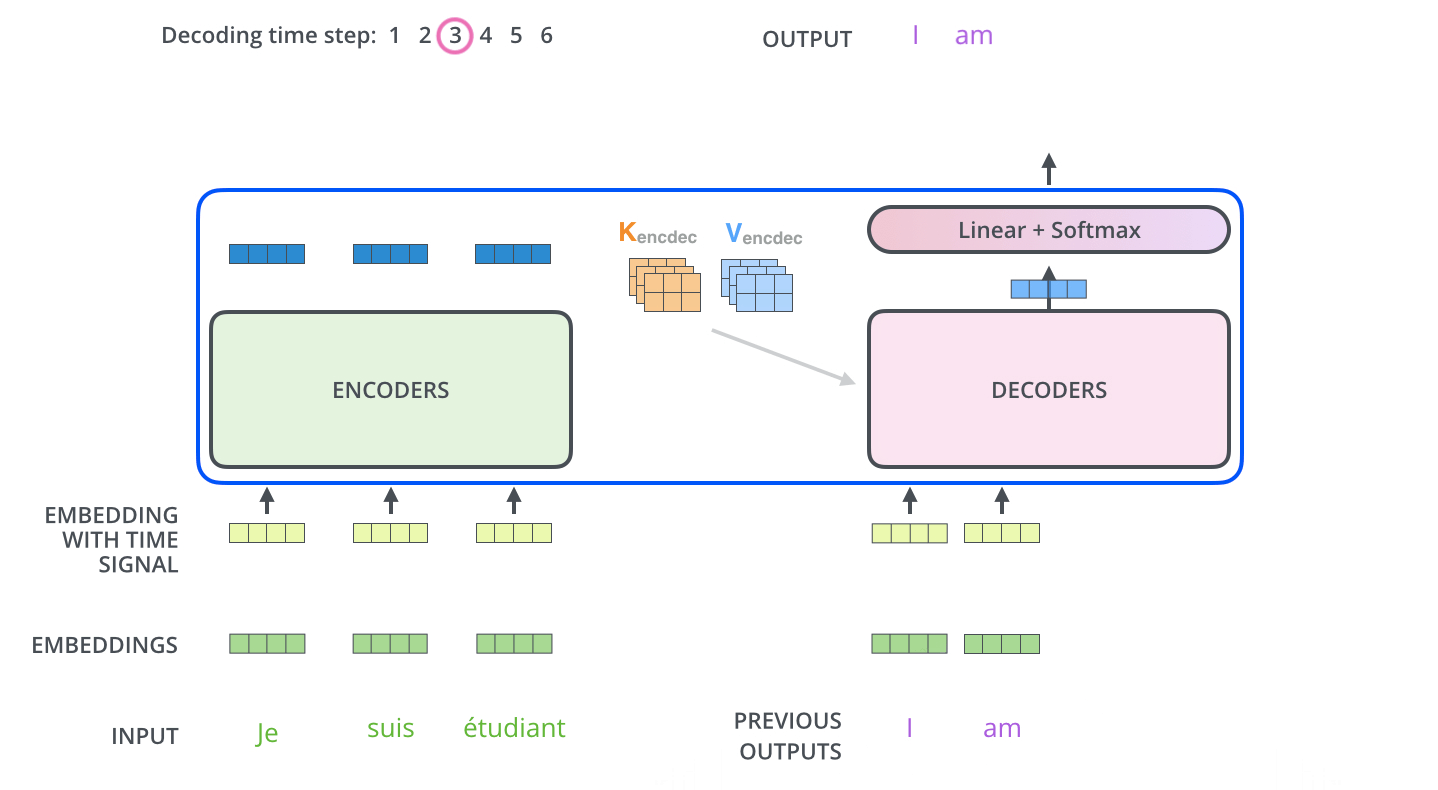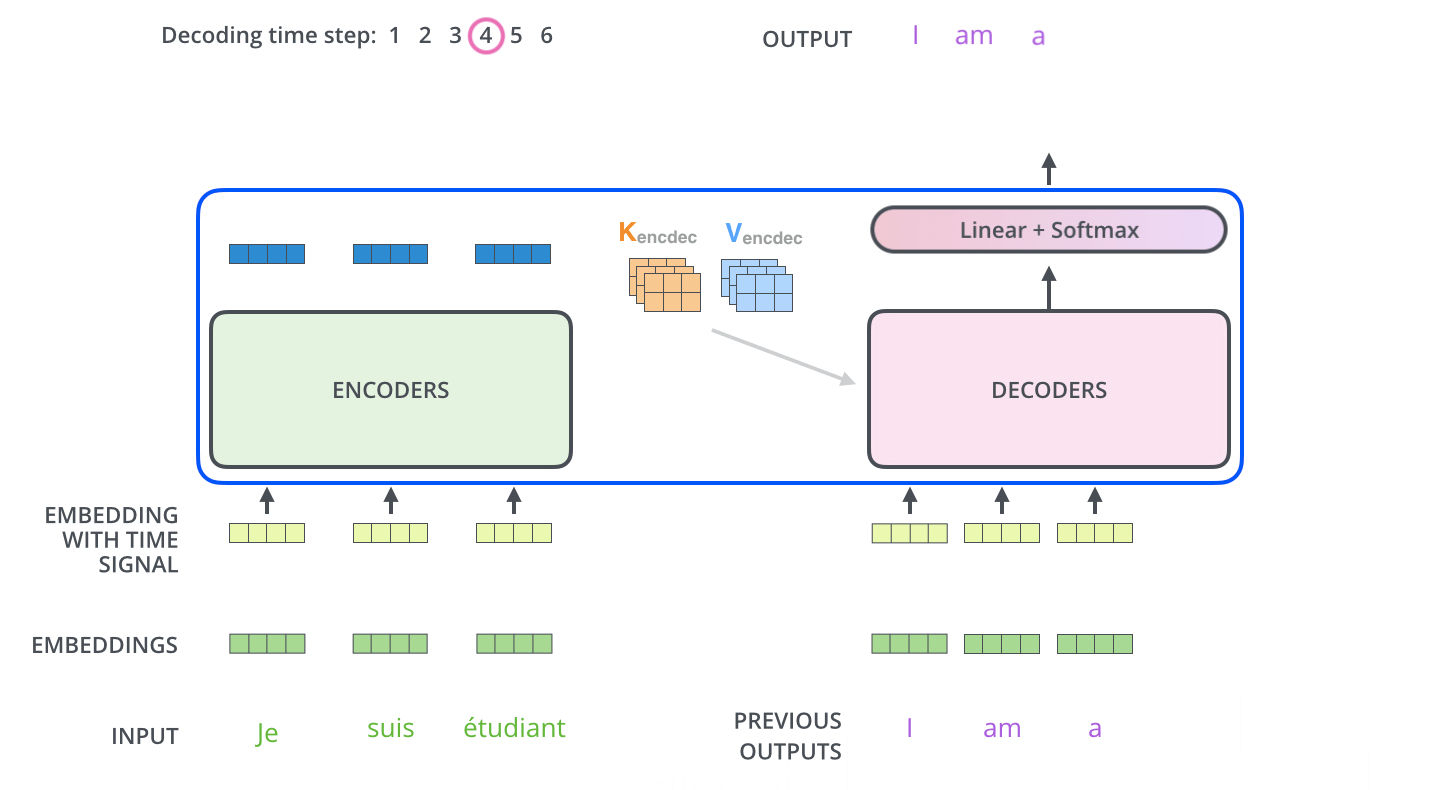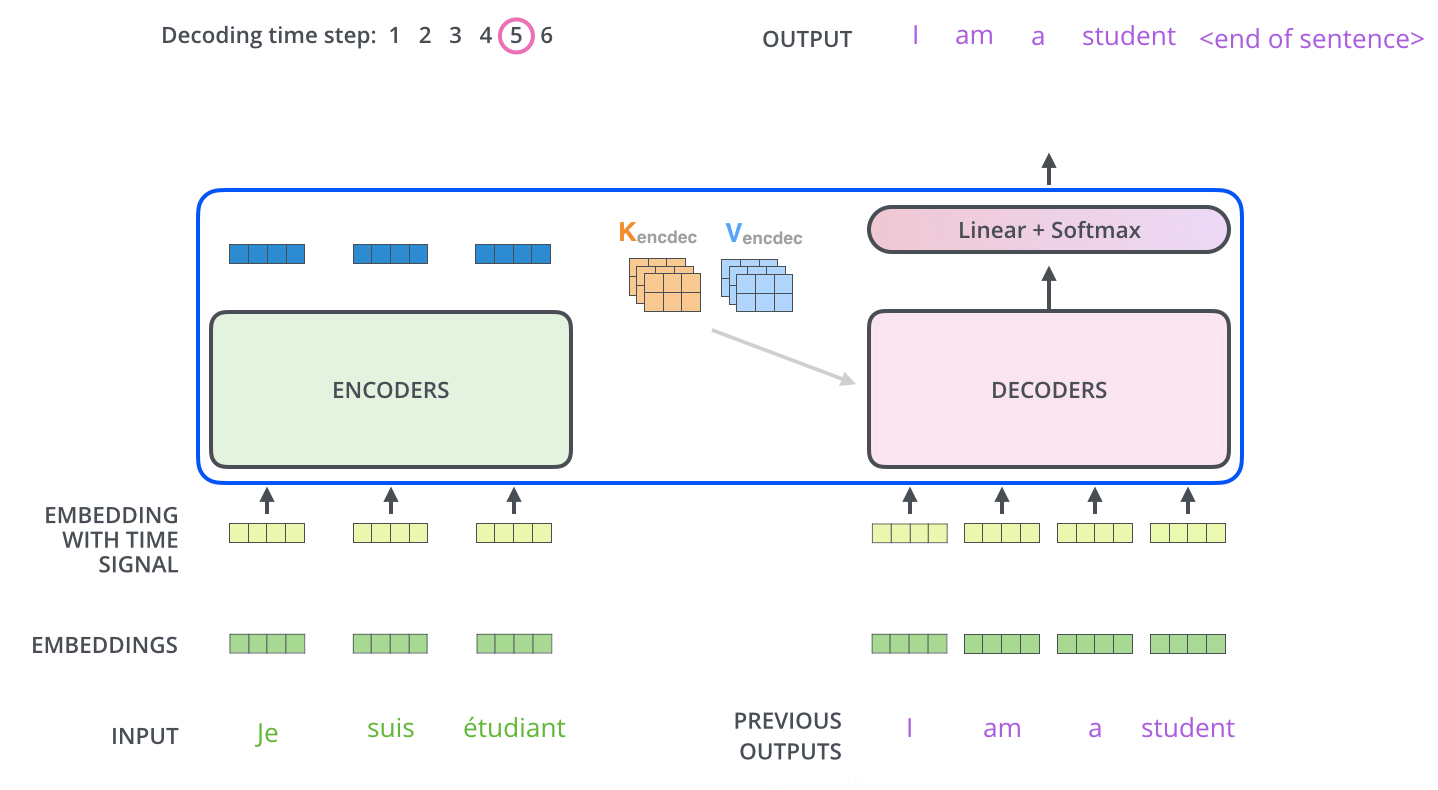
Decoder中的self attention与Encoder的self attention略有不同:
在Decoder中,self attention只关注输出序列中的较早的位置。可以在self attention计算中的softmax步骤之前屏蔽特征位置(设置为 -inf)来完成的。
“Encoder-Decoder Attention”层的工作方式与”Multi-Headed Self-Attention”一样,只是它从下面的层创建其Query矩阵,并在Encoder堆栈的输出中获取Key和Value的矩阵。(这里的 直觉就和一般的RNN的attention机制一样)
12.The Final Linear and Softmax Layer
Decoder的输出是浮点数的向量列表。我们是如何将其变成一个单词的呢?这就是最终的linear层和softmax层所做的工作。
linear层是一个简单的全连接神经网络,它是由Decoders产生的向量映射到一个更大的向量中,称为logits向量。
假设实验中我们的模型从训练数据集上得到的词表大小是10000(“Output Vocabulary”)。这对应的Logits向量也有1万维,每一维表示了一个唯一单词的得分。在线性层之后是一个softmax层,softmax将这些分数转换为概率。选取概率最高的索引,然后通过这个索引找到对应的单词作为输出。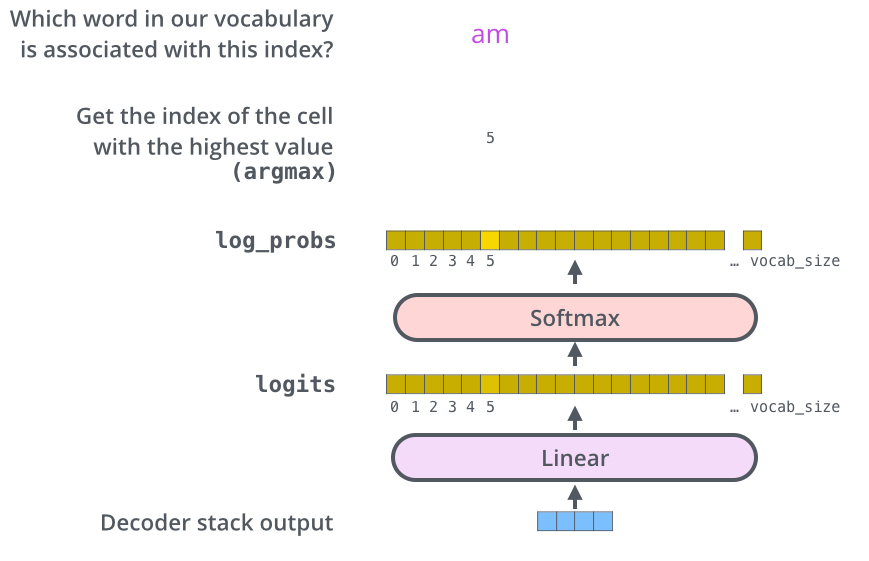
13.Recap Of Training
训练过程就跟一般的RNN一样,通过交叉熵和梯度下降来训练双语平行语料。
现在,因为模型一次生成一个输出,我们可以假设模型从该概率分布中选择具有最高概率的单词并丢弃其余的单词。
这里有2个方法:一个是贪婪算法(greedy decoding),一个是波束搜索(beam search)。波束搜索是一个优化提升的技术,可以尝试去了解一下,这里不做更多解释。
14.Go Forth And Transform
I hope you’ve found this a useful place to start to break the ice with the major concepts of the Transformer. If you want to go deeper, I’d suggest these next steps:
Read the Attention Is All You Need paper, the Transformer blog post (Transformer: A Novel Neural Network Architecture for Language Understanding), and the Tensor2Tensor announcement.
Watch Łukasz Kaiser’s talk walking through the model and its details
Play with the Jupyter Notebook provided as part of the Tensor2Tensor repo
Explore the Tensor2Tensor repo.
Follow-up works:
- Depthwise Separable Convolutions for Neural Machine Translation
- One Model To Learn Them All
- Discrete Autoencoders for Sequence Models
- Generating Wikipedia by Summarizing Long Sequences
- Image Transformer
- Training Tips for the Transformer Model
- Self-Attention with Relative Position Representations
- Fast Decoding in Sequence Models using Discrete Latent Variables
- Adafactor: Adaptive Learning Rates with Sublinear Memory Cost
本文仅作学习笔记。