论文:Supervised Learning of Universal Sentence Representations from Natural Language Inference Data
基于Natural Language Inference任务(有监督的语句嵌入模型)
传统的语句嵌入方法(sentence2vec)往往采用的是无监督学习方法,然而无监督的学习方法在较长语句向量的获得方面表现得不够优异。这篇文章中,我们将介绍一种有监督的训练方法(以Stanford Natural Language Inference Datasets为训练集),实验表明,这种方法要优胜于skip-thought方法(一种encoder-decoder模型)。
本文采用的是Stanford Natural Language Inference Datasets,简称SNLI。SNLI包含570K个人类产生的句子对,每个句子对都已经做好了标签,标签总共分为三类:蕴含、矛盾和中立(Entailment、contradiction and neutral)。
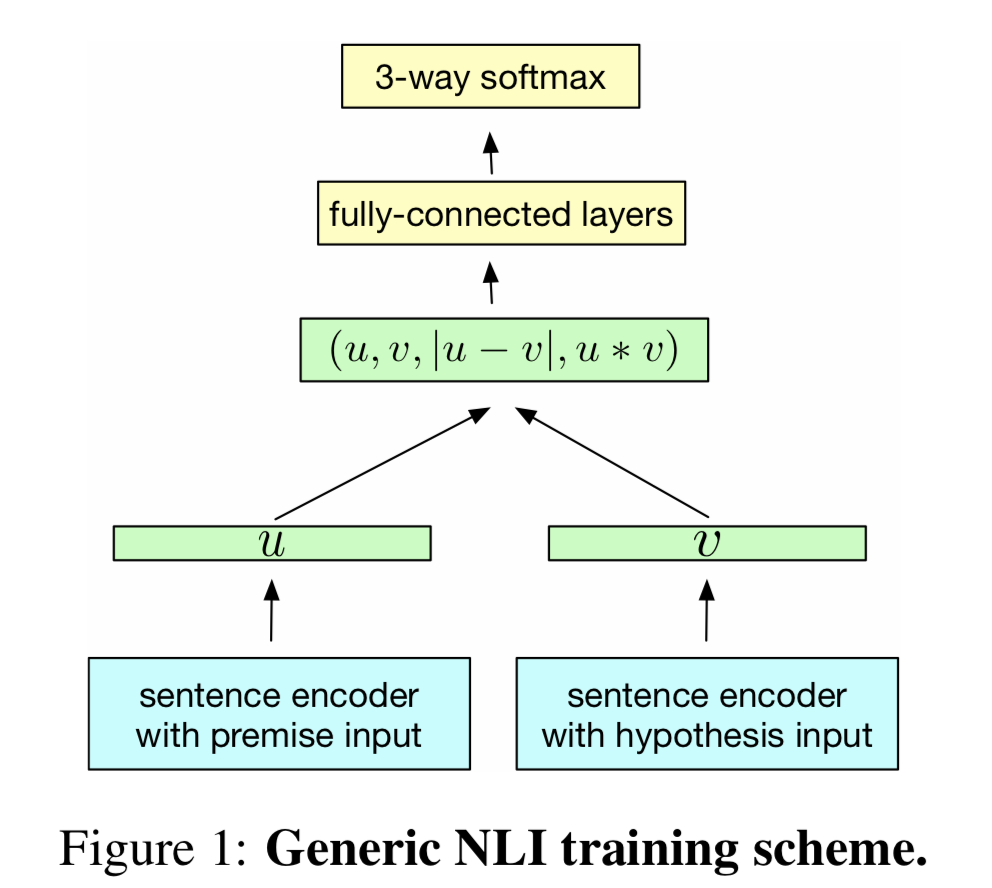
从上图来看模型还是很简单的,其中特别一点的是有一层把句子向量进行了一些组合拼接。
最终训练的得到词向量也可迁移到其他任务上使用。
这个模型主要目的是为了得到句子向量,我们不关注模型最终的预测效果优异性。重点是模型得到的encoder获取的句子向量很好地表达了句子意义。这些句子向量在一些下游任务中有很好的表现。(取两个句子向量的余弦相似度,就能得到很好的文本相似度和语义匹配结果。)
InferSent的官方代码可以从GitHub上找到。
1 |
|
1 |
|