基于表征的匹配(Representation-based Match)
该方式下,更侧重对表示层的构建,尽可能充分地将待匹配的两端都转换到等长的语义表示向量里。然后在两端对应的两个语义表示向量基础上,进行匹配度计算,我们设计了两种计算方法:一种是通过固定的度量函数计算,实际中最常用的就是 cosine 函数,这种方式简单高效,并且得分区间可控意义明确;还有就是将两个向量再过一个多层感知器网络(MLP),通过数据训练拟合出一个匹配度得分,这种方式更加灵活拟合能力更强,但对训练的要求也更高。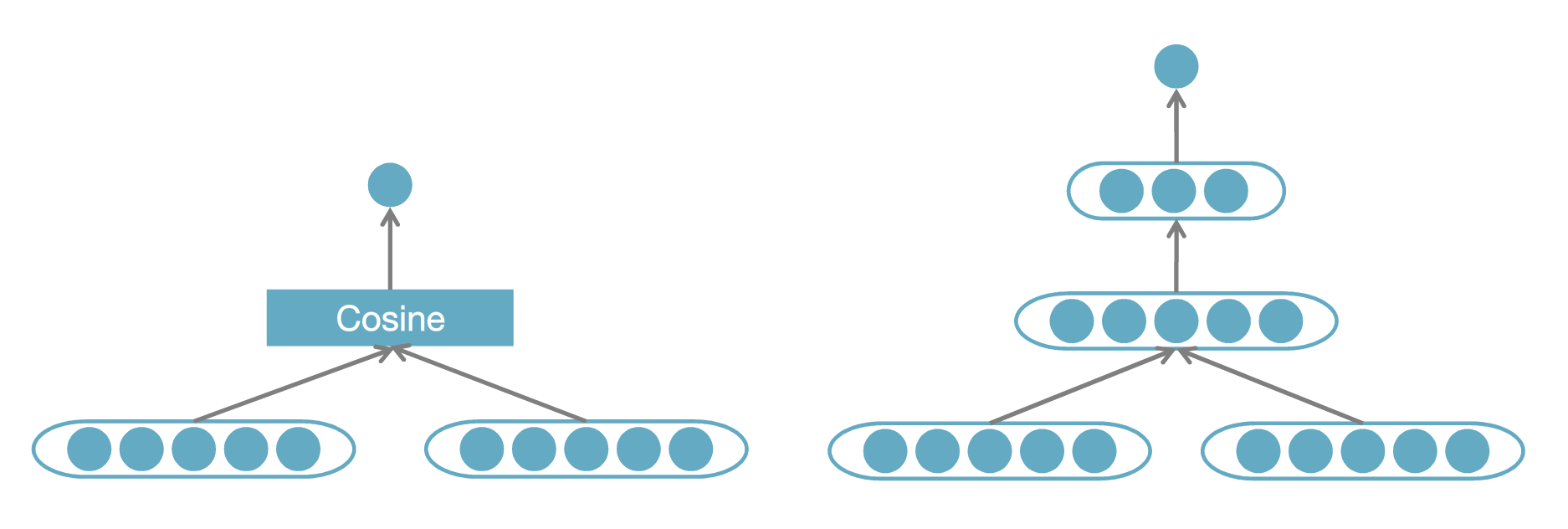
基于交互的匹配(Interaction-based Match)
该方式更强调待匹配两端更充分的交互,以及交互基础上的匹配。所以不会在表示层将文本转换成的一个整体表示向量,而一般会保留和词位置相对应的一组表示向量。例如: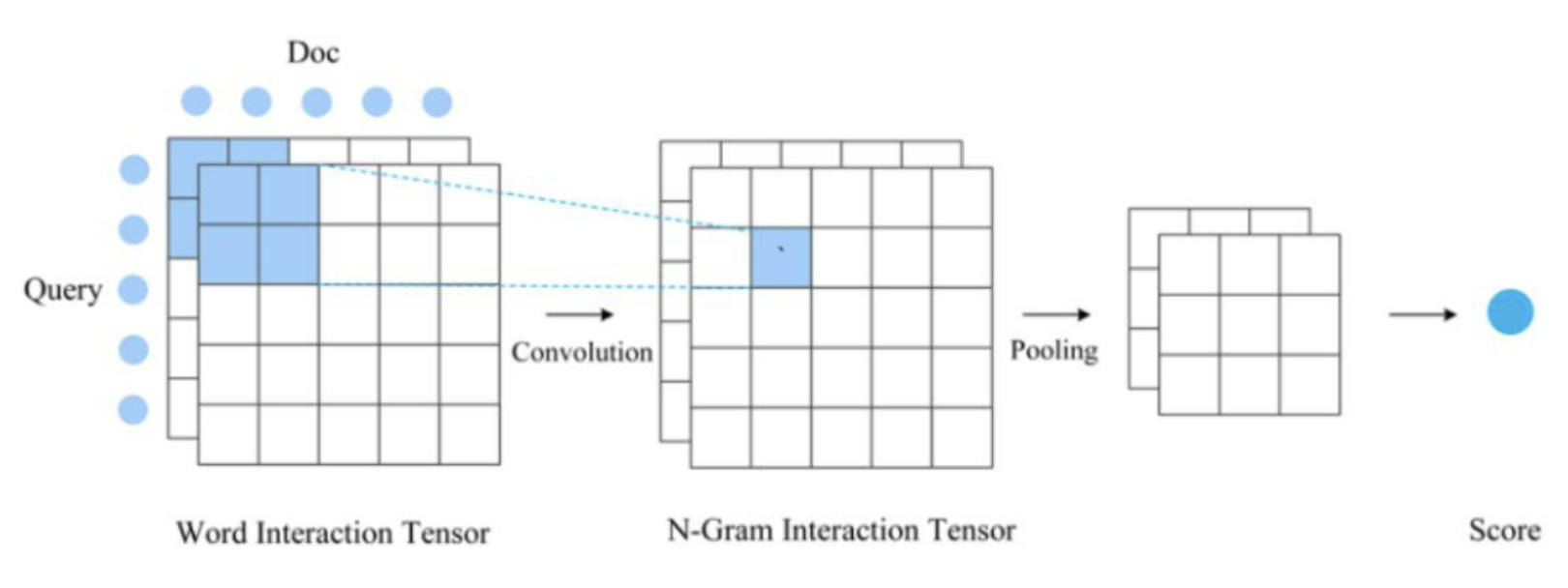
nteraction-based Match 匹配方法匹配建模更加细致、充分,一般来说效果更好一些,但计算成本会增加非常多,适合一些效果精度要求高但对计算性能要求不高的应用场景。大部分场景下我们都会选择更加简洁高效的 Representation-based 匹配方式(像句子level的,由于句子是短文本,一个vector就很容易把句子的内容保存下来,R-b就有很好的表现)。