模型详解
DSSM的全称是Deep Structured Semantic Model或者Deep Semantic Similarity Model。
DSSM由微软研究院深度学习研究中心开发,是一个利用深度神经网络把文本(句子,queries,实体等)表示成向量,并且计算文本相似度的模型和方法。
DSSM在信息检索和网络文本排序中有广泛的应用(Huang et al. 2013; Shen et al. 2014a,2014b; Palangi et al. 2016), 广告相关性, 实体搜索和有趣性任务(Gao et al. 2014a, 问答(Yih et al., 2014), 图片描述(Fang et al., 2014), 以及机器翻译 (Gao et al., 2014b) etc.
这个模型就如他的名字描述一样,有一个较深的模型结构的网络。DSSM来自微软研究院,当初她要解决怎么样能够model我们的搜索的关键词和被点开的连接的文本的标题的相关性(这里用相关性比相似度更贴切)。他们用微软必应搜索引擎的用户数据来训练这个模型。
- 利用搜索关键词和点开的链接标题训练文本相似度。
- 基本假设:用户搜索的关键词和最终点开的网页标题含义相近
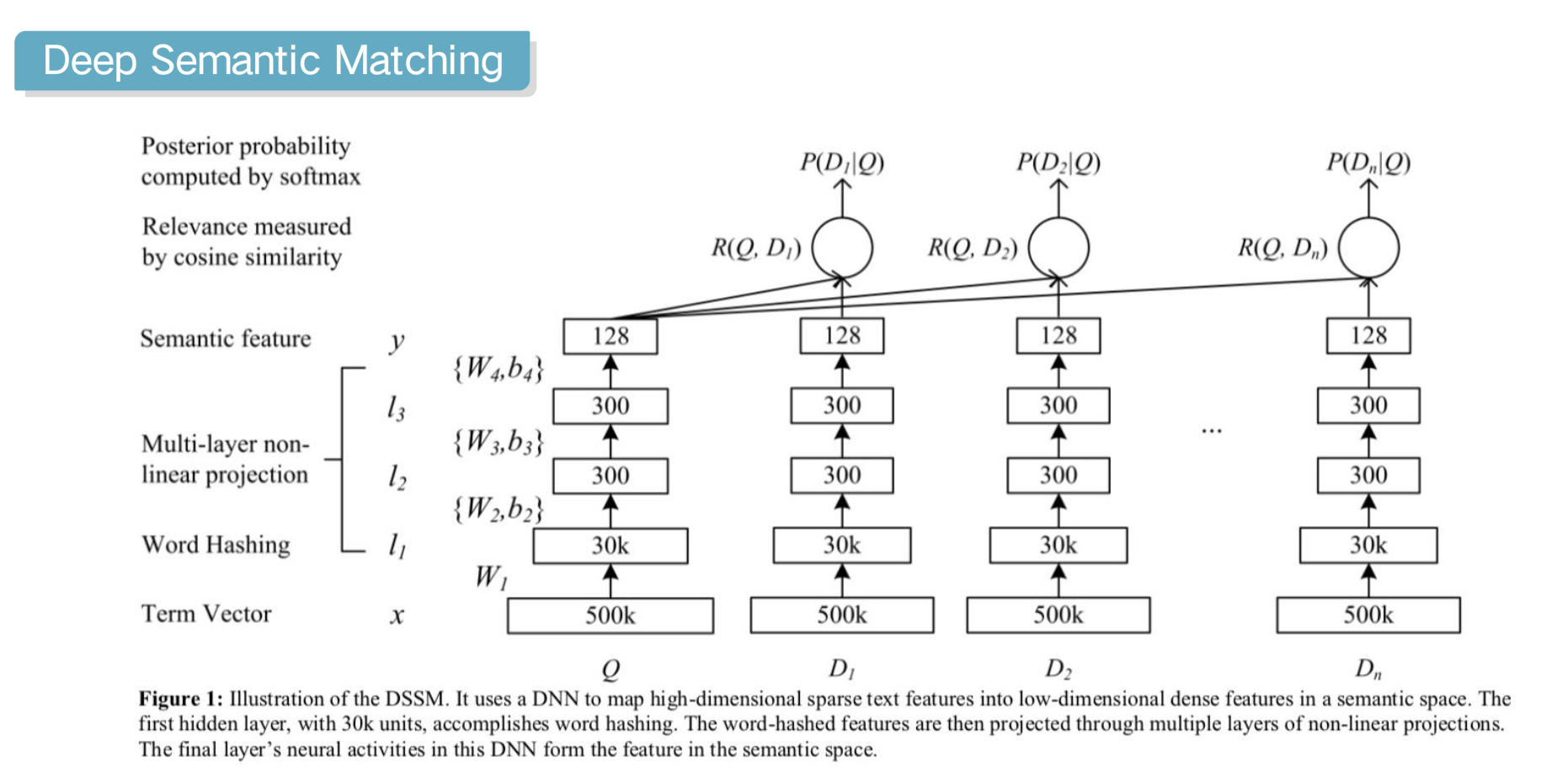
模型结构看起来有点复杂,但是还是遵从feature vector和余弦相似度这样的架构。它的主要套路是先把我们搜索的关键词Q(query)encode成一个vector,再把用户可能点开的一些D(document)也encode成vector。
从输入层往上看,最底层的500k指的是使用的可能是一个500k的词汇表,我们可以用类似bag-of-word这样的vector作为输入,然后经过一个Word Hashing(后面会细讲),把输入映射到30k维,再经过三层的隐层,转为128维的语义特征(Semantic feature)。我们同时得到Q和若干个D(5个用户点开的,4个用户没有点开的)的语义特征,再把Q和D分别的做余弦相似度,最后过sofemax转成概率。最后的目标是希望被点开的D和Q的余弦相似度尽量高,没有点开的尽量低。
Word Hashing
- 用于解决单词表和out of vocabulary问题
- 把单词(e.g. good)前后加上#(#good#)
- 然后去所有的trigram(#go,goo,ood,od#),表示成bag of trigram向量
就可以把很高维的词表降到一个较低维的词表。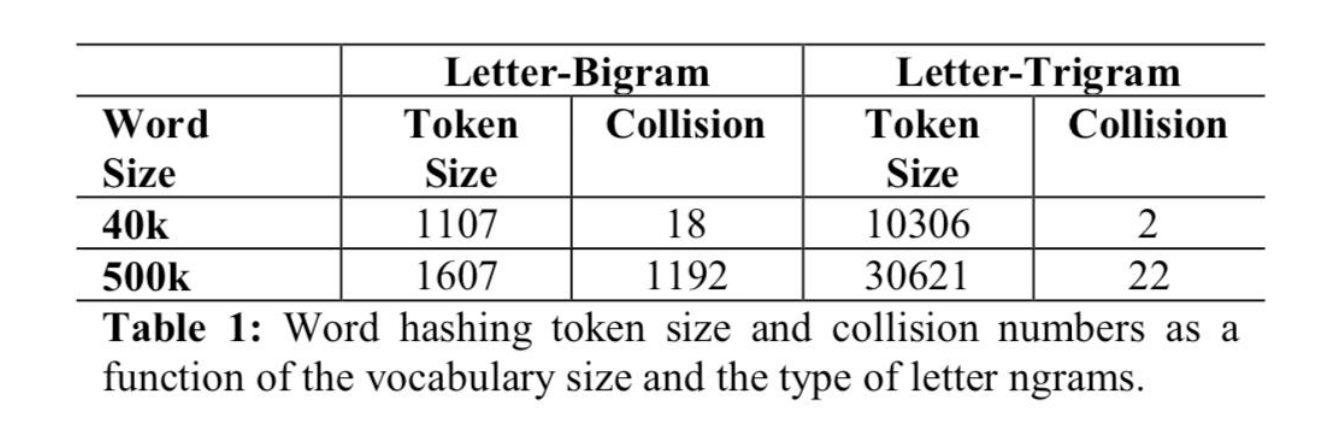
如上图,500k的做完word hashing 后降为300k,同时模型的参数也可以降低。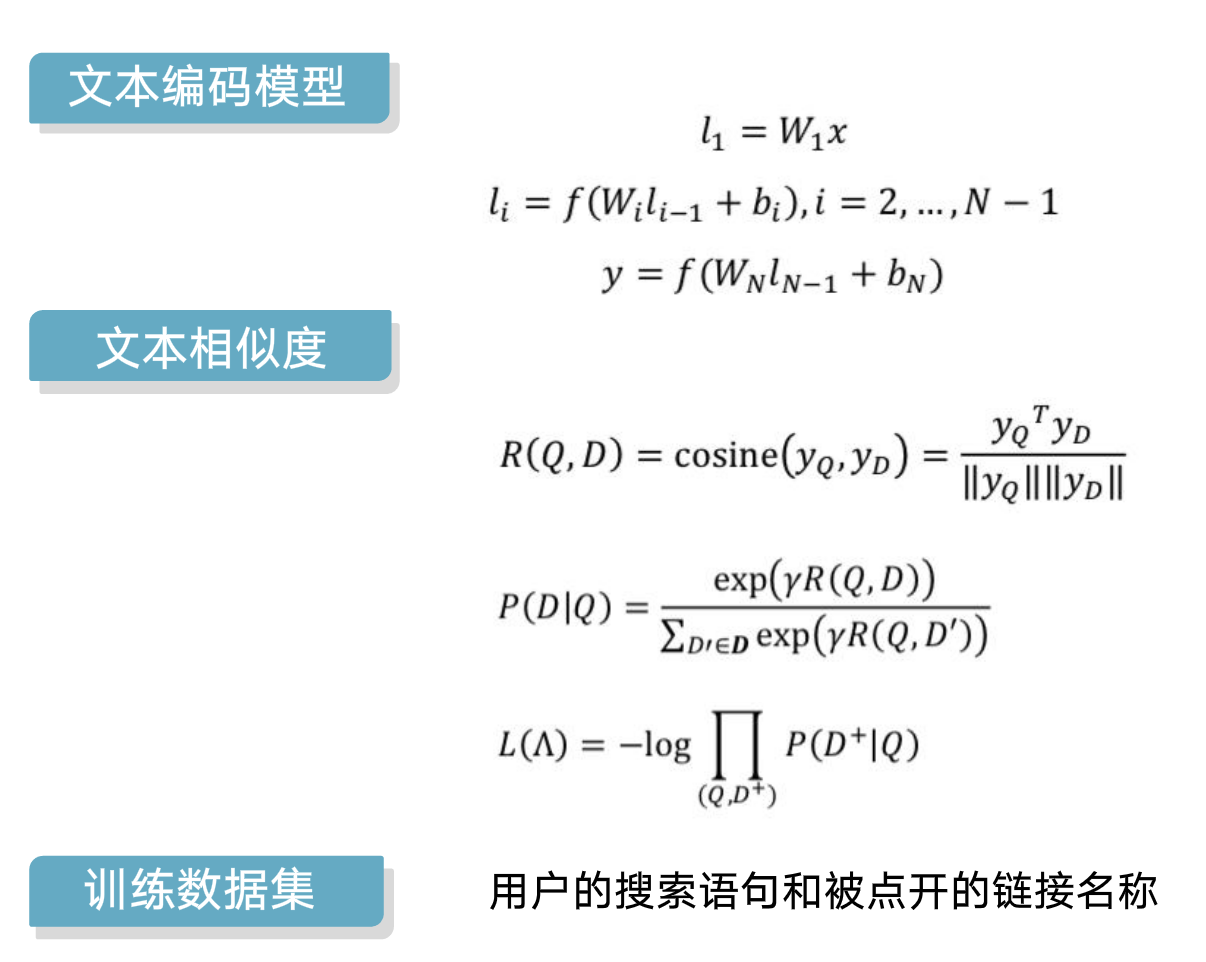
上面式模型的相关函数。观察可以发现,第一层隐层没有用激活函数,后面几层都是用的tanh,然后计算一个cosine,用sofemax转为概率。损失函数的意思是被点开的D(+)的概率要尽可能高。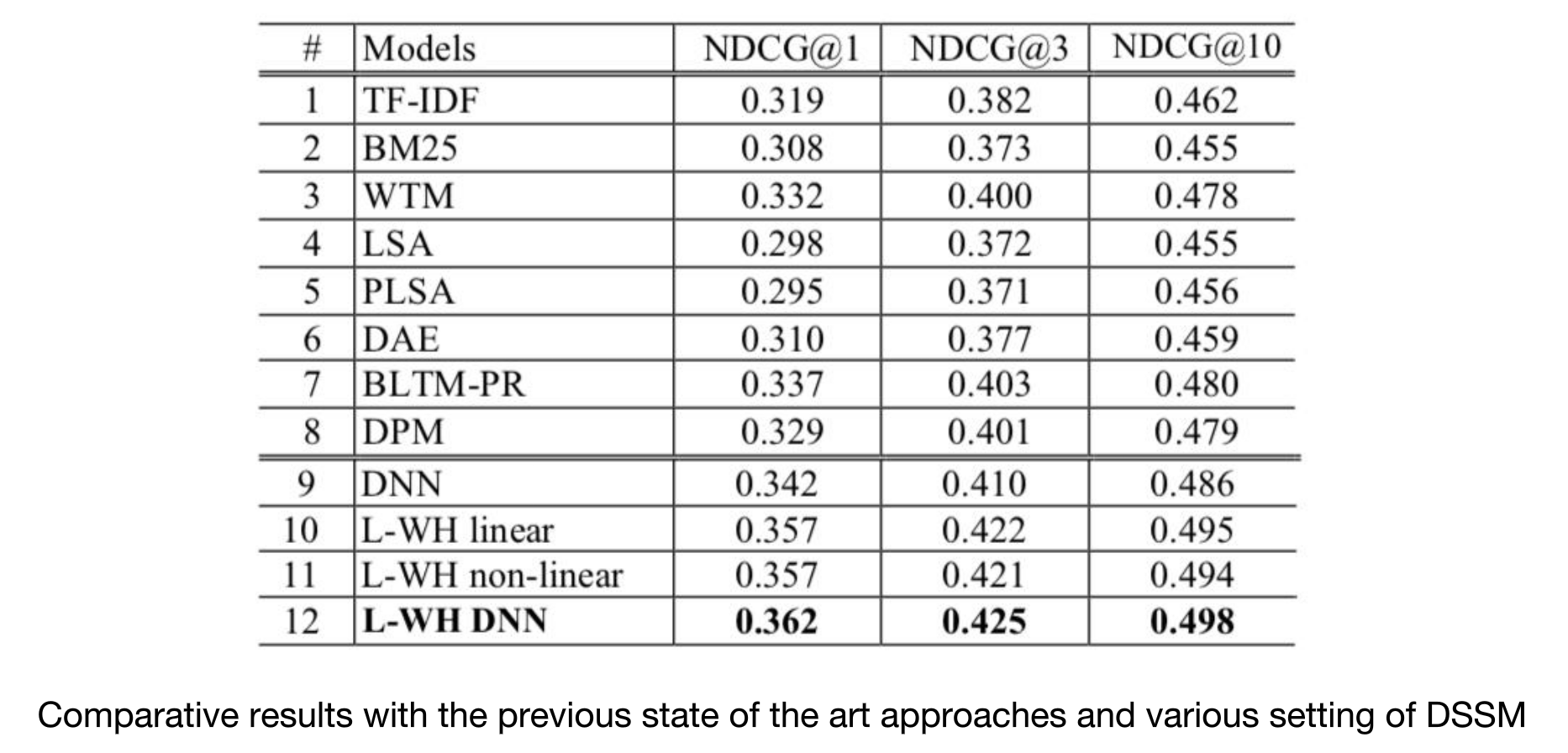
和我们最熟悉的TF-IDF模型相比较,发现有较大的提升,在当时是stateoftheart的。